
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
Tags
- first pg on this rank that detected no heartbeat of its watchdog.
- 토픽모델링
- doubleml
- Time Series
- Transformer
- 분산 학습
- 딥러닝
- pytorch
- causal machine learning
- netflix thumbnail
- NTMs
- 인과추론
- causal forest
- 리뷰
- causal reasoning
- machine learning
- gru-d
- causal ml
- GaN
- 불규칙적 샘플링
- multi gpu
- nccl 업데이트
- causal inference
- causal transformer
- 인과추론 의료
- 의료정보
- nccl 업그레이드
- ERD
- irregularly sampled time series
- 의료
Archives
- Today
- Total
데알못정을
강화 학습이란 본문
728x90
강화 학습 스터디) 노승은 저자의 바닥부터 배우는 강화학습 정리입니다.
인공지능 혹은 AI 라고 하는 것 → 학술적으로 엄밀히 정의되지 않는, 대중적인 용어
기계학습 → 인공지능을 구현하는 하나의 방법론. 즉, 인공지능을 꼭 기계 학습으로만 구현해야 하는 것인 아님!
- 예컨데 게임 속 몬스터의 지능을 만든다고 할 때, 간단한 룰 베이스 알고리즘을 적용해도 인공 지능을 구현했다고 볼 수 있음
- 룰 베이스 알고리즘은 모든 상황에 대해서 규칙을 구현해야 한다는 단점이 있음
- 그래서 기계학습을 사용 → 모든 상황에 대해서 규칙을 만들지 않아도 인공 지능을 만들 수 있다!(강화학습, 지도학습, 비지도학습이 여기에 속함!)
지도 학습과 강화 학습의 차이
- 지도 학습: 입력 데이터에 대응 되는 정답이 있을 때, 입력 데이터와 정답 사이의 관계를 학습하는 것
- 학습 데이터를 가지고 입력과 정답 사이의 관계를 학습하고, 모델이 본 적이 없는 새로운 테스트 데이터(unseen)를 바탕으로 학습 데이터를 통해 배운 지능으로 정답을 추론 하는..
- 강화 학습: 입력 데이터에 대응 되는 정답이 없음! (정답을 알려줄 선생님이 없어요) 때문에 모든 지식을 모델 혼자서 터득해야함
- 쉬운 말 : “시행 착오를 통해 발전해 나가는 과정”
- 어려운 말: “순차적 의사결정 문제에서 누적 보상을 최대화 하기 위해 시행 착오를 통해 행동을 교정하는 학습 과정”
- 즉, 강화 학습이 풀고자 하는 문제는 순차적 의사결정(sequential decision making) 문제임
Concept 1. 순차적 의사결정 문제 (sequential decision making)
어떤 행동(의사결정)을 하고, 그로 인해 상황이 바뀌고, 다음 상황에서 또 다시 어떤 행동을 하고 … 이처럼 각 상황에 따라 하는 행동이 다음 상황에 영향을 주며, 결국 연이은 행동을 잘 선택해야 하는 문제가 바로 순차적 의사결정 문제임
Concept 2. 보상(reward)
의사결정을 얼마나 잘하고 있는지 알려주는 신호임. 강화학습의 목적은 과정에서 받는 보상의 총합, 즉 누적 보상(cumulative reward)을 최대화 하는 것임
- 로봇이 안 넘어지고 1m를 갈 때마다 +1이라는 식으로 보상을 정할 수 있음
[보상의 특징]
- 어떤 행동에 대해 “얼마나” 잘하고 있는 지 알려줄 뿐, “어떻게”해야 높은 보상을 얻을 수 있는지는 알려주지 않음
- 그런데도 학습을 할 수 있는 이유→시행착오
- 이런 저런 시도를 해보다가, 처음으로 3m를 갔을 때 높은 보상을 받음으로써, 방금의 행동이 좋은 행동이었음을 기억 → 더 자주하도록 교정
- 이런 상황에서 3m보다 짧은 거리에서 넘어졌다면 이전 과정에서 받았던 보상보다 적게 받고, 방금의 행동이 좋지 않은 행동이었음을 기억 → 방금 했던 행동을 덜 하도록 교정
- 즉 보상이라는 신호를 통해 취했던 행동에 대해 평가할 수 있기 때문에 높은 보상을 받았던 행동은 더 하고, 낮은 보상을 받았던 행동은 덜 하면서 보상을 최대화 하도록 수정할 수 있음 → 결국에는 이것이 “지능”이 됨(사람과 많이 닮아 있다)
- 그런데도 학습을 할 수 있는 이유→시행착오
- 보상은 벡터가 아닌 스칼라
- 강화 학습은 스칼라 형태의 보상이 있는 경우에만 적용할 수 있음
- 학점(x) 연애(y) 동아리(z)를 모두 잘하고 싶으면 하나의 스칼라로 더 잘하고 싶은 항목에 가중치를 두어 0.5x + 0.25y + 0.25z 로 표현
- 강화 학습은 스칼라 형태의 보상이 있는 경우에만 적용할 수 있음
- 보상이 주어지는 타이밍이 다양할 수 있음
- 행동을 취하자 마자 바로 받을 수 있는 보상이 정의 되는 문제 (학습에 easy)
- 바둑과 같이, 모든 수를 놓고 나서 승, 패라는 보상이 정의되는 문제 (hard) → 어떤 행동이 중요했는지 책임 소재가 불분명해져서 학습에 어려움
- 위 두가지 경우와 같이 선택했던 행동의 빈도에 비해 훨씬 가끔 주어지거나 한참 뒤에 주어질 수도 있음
- 이런 경우 “보상이 희소하다(sparse)” 라고 표현
- 밸류 네트워크 등의 다양한 아이디어가 등장
- 지도 학습과 다르게, 강화 학습에서 다루는 문제는 순차적 의사결정 문제이기 떄문에 순차성, 즉 시간에 따른 흐름이 중요하고 이 흐름에서 보상이 뒤늦게 주어지는 것이 가능
Concept 3. 에이전트와 환경, 상태
- 에이전트: 강화 학습의 주인공이자 주체, 학습하는 대상
- 환경: 에이전트를 제외한 모든 요소, 상태 변화(state transition)을 일으키는 역할
- 상태: 과거의 행동으로 현재 환경이 변했을 때, 현재 상태에 대한 모든 정보를 숫차로 표현한 것 (현재 로봇의 위치, 기울어진 정도, 각도 등)
- 강화 학습의 과정
- 현재 상황 $s_{t}$에서 어떤 액션을 해야할 지 $a_{t}$를 결정
- 결정된 행동 $a_{t}$를 환경에 반영
- 환경으로부터 그에 따른 보상 $r_{t+1}$과 행동의 결과로 변화된 다음 상태 $s_{t+1}$의 정보를 받음
- 1 loop 끝 → 한 틱(tick)이 지났다
- 강화 학습의 과정
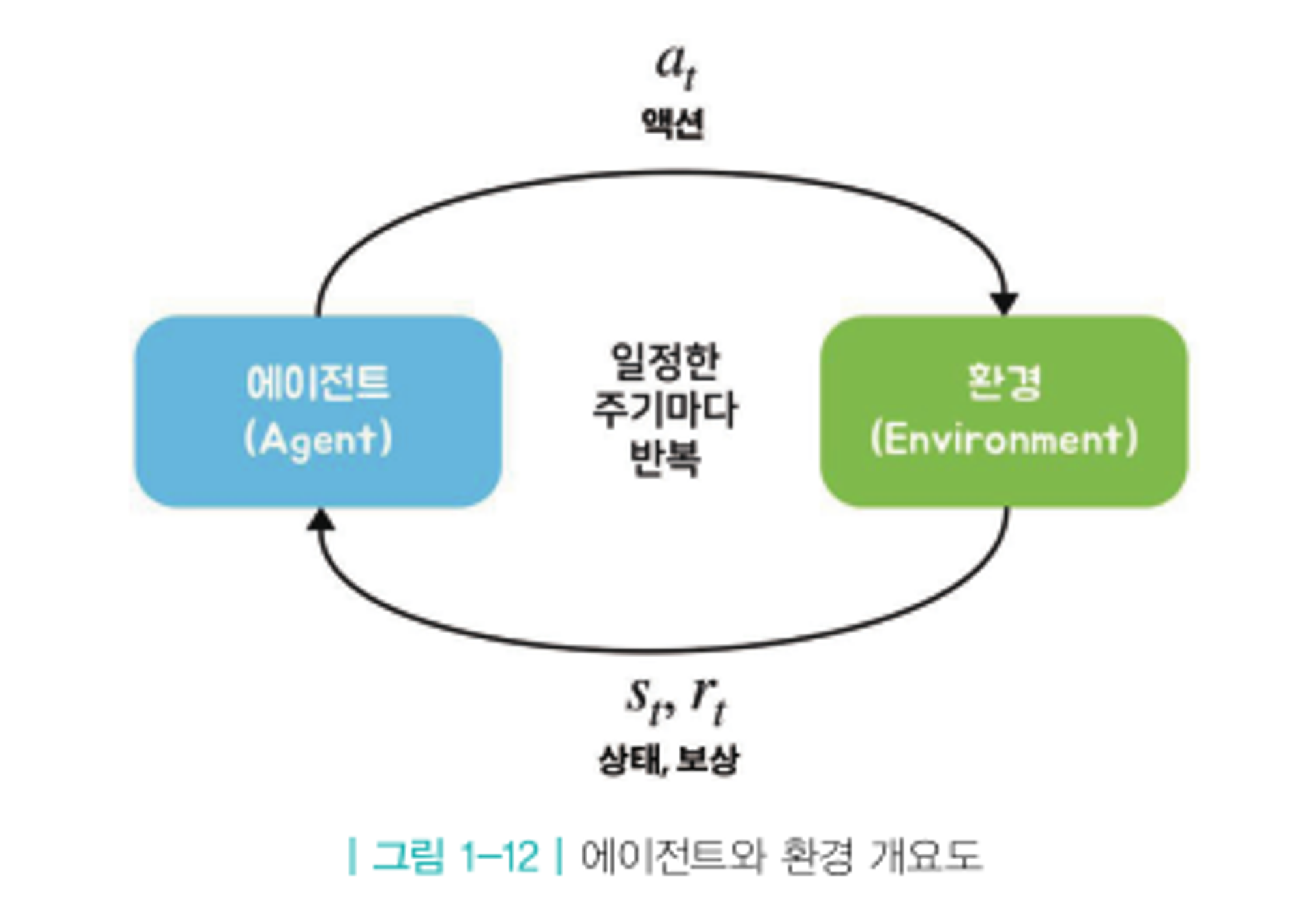
- 실제 세계에서는 시간의 흐름이 연속적(continuous)지만, 순차적 의사결정 문제에서는 시간의 흐름을 이산적(discrete)로 생각 → 그때의 시간의 단위를 tick 혹은 time step이라고 함
참고 문헌
바닥부터 배우는 강화 학습 - 노승은
728x90
'Reinforcement Learning' 카테고리의 다른 글
| MDP를 모를 때 밸류 평가하기 1 - 몬테카를로 학습 (1) | 2024.01.29 |
|---|---|
| MDP를 알 때의 플래닝 (0) | 2024.01.29 |
| 벨만 방정식 (1) | 2024.01.29 |
| 마르코프 결정 프로세스 (2) | 2024.01.29 |
'Reinforcement Learning' Related Articles
more




Comments