
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- multi gpu
- 딥러닝
- first pg on this rank that detected no heartbeat of its watchdog.
- pytorch
- 리뷰
- operation management
- queueing theory
- nccl 업데이트
- 의료정보
- irregularly sampled time series
- 분산 학습
- m/m/s
- GaN
- Transformer
- ERD
- pre-trained llm
- 불규칙적 샘플링
- NTMs
- length of stay
- nccl 업그레이드
- gru-d
- timesfm
- Time Series
- nccl 설치
- moirai
- 대기행렬
- 패혈증 관련 급성 호흡곤란 증후군
- 토픽모델링
- timellm
- ed boarding
Archives
- Today
- Total
데알못정을
DB 설계 및 HeidiSQL을 이용한 DB 구현 PART4: DB 제작 하기 본문
728x90
프로젝트였던 ERD 작성과 이를 HeidiSQL을 파이썬과 연동하여 DB를 만들어보고, 잠재적 사용자가 사용할 VIEW를 제공하는 과정을 기록한다.
0. 프로젝트 배경
-
어떤 사이트 A는 고객이 사업체에 대한 리뷰를 작성하는 플랫폼이다. 사이트 고객(사용자)들은 자신이 이용한 여러 유형의 사업체에 대한 리뷰를 남기고 고객끼리 리뷰를 공유하며 교류할 수 있다. 본 프로젝트는 사이트 A가 사용하는 DB의 ER diagram 도식화와 DB 구현을 목적으로 한다.
- ERD 작성하기
-
사이트 A가 사용하는 DB에 대한 ER diagram을 도식화하는 것을 목표로 한다. 사이 트 A의 DB는 아래의 requirement들을 만족해야 한다.
(R1-1) 사이트 A는 사이트에 가입된 사용자에 대한 정보를 저장하고 있다. 사용자는 사업체를 이용한 후 리뷰 혹은 팁을 작성할 수 있다. 고객에 대한 정보로는 자체적으로 부여한 고유번호, 사이트 이용 시작 시점, 작성한 리뷰의 평균 별점, 고객의 리뷰들이 각각 재밌다고, 유용하다고, 근사하다고 평가한 수와 사용자의 팬이라고 답한 다른 사용자 수 정보가 저장되어야 한다.
-> 고유번호는 고유한 값이기 때문에 User_id라는 key 값으로 설정, key 값을 가지기 때문에 사용자는 User를 강한 entity type로 설정, 나머지 저장되어야 하는 정보는 attribute로 설정하였다. 사용자는 사업체를 이용한 후 리뷰 혹은 팁을 작성할 수 있다고 하였기 때문에 Tips와 Reviews라는 relation을 두었음
(R1-2) 사이트 A는 사이트에 등록된 사업체에 대한 정보를 저장하고 있다. 사업체에 대한 정보 로는 사업체 고유 번호, 현재 운영 여부, 위치 도시, 고객들로부터 받은 평균 별점, 고객들로부터 받은 리뷰 개수의 정도 정보가 저장되어야 한다. 사이트 A는 또한 각 사업체의 카테고리 정보와 특성 정보를 갖는다. 카테고리 정보는 사업체의 사업 유형을 나타내고 특성 정보는 특정 속성( ex) wi-fi 있음 등)의 여부를 나타낸다. 특성 정보는 여부의 수준이나 정도를 나타내는 특성 값을 갖는 다. 카테고리와 특성 정보, 특성값도 저장되어야 한다.
->사업체 고유 번호는 고유한 값이기 때문에 Business_id라는 key 값으로 설정, key 값을 가지기 때문에 사업체는 Business라는 강한 entity type 설정, 나머지 저장되어야 하는 정보는 attribute로 설정, 사업체의 카테고리 정보는 Categories라는 강한 entity type를 만들고 Business Cateogries 라는 relation을 설정하여 사이트 A상에 저장된 것을 ER diagram에 표현하였다. 마찬가지로 특성 정보도 Attributes라는 강한 entity type을 만들고 Business attributes라는 relation을 설정하여 표현하였다.
(R1-3) 사이트 A는 시간과 시점에 대한 정보를 저장하고 있다. 따라서 연도 정보와 요일 정보가 저장되어야 한다. 시간과 관련된 정보로는 사업체의 개장시간과 폐장 시간, 그리고 고객의 엘리트 고객 선정 시점(연도)가 저장되어야 한다.
-> 요일 정보는 days 라는 강한 enity type으로 설정하였고 요일 정보와 연관이 있는 것은 사업체 이므로 Business와 days간의 Business hours라는 relation을 두고, Business hours의 attribute로 opening_time, closing_time으로 두어 개장시간과 폐장시간도 저장하고 있다는 것을 표현, 연도 정보는 years라는 강한 enity type으로 설정하였고 연도 정보와 연관이 있는 것은 사용자 이므로 User와 years 간의 elite라는 relation을 두어 고객의 엘리트 선정 시점 정보도 저장하고 있다는 것을 표현하음.
(R1-4) 사이트 A는 사용자가 사업체에 남긴 리뷰에 대한 정보를 저장하고 있다. 리뷰에 대한 정 보로는 리뷰 고유 번호, 사업체 id, 고객 id, 리뷰의 별점, 리뷰들이 각각 재밌다고, 유용하다고, 근 사하다고 평가된 정도, 리뷰의 길이 정도 정보가 저장되어야 한다. 사이트 A는 리뷰 뿐 아니라 조 금 더 축약된 형태의 리뷰인 팁 정보도 저장하고 있다. 팁에 대한 정보로는 사업체 id, 고객 id, 좋아요 수, 팁의 길이 정도 정보가 저장되어야 한다.
-> R1-1에서 설정해놓은 Reviews, Tips relation에 각각 저장되어야 하는 정보를 attribute로 설정하였음.
(R1-5) 사이트 A는 고객들의 부가정보를 저장하고 있다. 부가 정보로는 먼저, 고객들의 엘리트 고객 선정 시점이 저장되어야 하고, 또 다른 정보로는 고객의 칭찬받은 정보(사진 등)와 그 개수 의 정도가 저장되어야 한다.
->고객들의 엘리트 선정 시점에 대한 정보는 R1-3에서 저장됨, Compliments라는 강한 entity type을 만들고 Compliment_id는 고유한 값이므로 key attribute, Compliment_type라는 attibute를 설정, User와 Compliments 간의 User compliments라는 relation을 두고 relation에 Number_of_compliment라는 attribute를 두어서 고객의 칭찬받은 정보와 그 개수의 정도가 저장되었다는 것을 표현함.
-
각 요구사항에 맞게 그린 ERD

ERD

attribute 와 참조 관계
1. DB 구현 및 데이터 입력
(R2-1) 사이트 A의 데이터를 활용하기에 앞서 이를 MySQL 상에 저장해야 한다. 이를 위해 먼저 ISA_team##의 이름을 가지는 schema를 생성해야 한다. 예를 들면, 1조의 schema 명은ISA_team01이다. 이 때 schema가 존재할 경우 생성 과정을 다시 수행하지 않아야 한다.

만약 schema가 존재할 경우 생성 과정을 다시 수행하지 않도록 IF NOT EXISTS를 이용하여서 schema를 생성하였다.
(R2-2) Schema를 설계한 이후에는 데이터를 저장하기 위한 table을 생성해야 한다. 생성하는 table과 column 이름과 순서는 주어진 데이터셋의 table 및 column과 일치해야 한다. 0 또는 1의 값을 가지는column은 TINYINT(1)로, INTEGER type는 ‘INT(11)’로, STRING type는 ‘VARCHAR(255)’을 이용하여 생성한다. 255자를 넘는 경우 ‘LONGTEXT’를 이용하여 생성한다. 그 외 날짜시간은 ‘DATETIME’을 통해 생성한다. 이 때 table이 존재할 경우 생성 과정을 다시 수행하지 않아야 한다. (R2-2)에서는 foreign key 조건을 작성하지 않고 (R2-3)에서 데이터 입력 후 foreign key 조건을 추가한다.

모든 테이블들은 IF NOT EXISTS를 통해서 테이블이 존재한다면 다시 생성되지 않도록 하였다. 또한, 조건에 알맞게 숫자형의 경우는 INT(11)로, 문자형의 경우에는 VARCHAR(255)를 이용해 생성하였다. 불러오는 csv파일이 14개에 대응되는 테이블에 맞추어서 14개의 테이블을 생성하였고, 테이블을 생성할 때 Primary key에 대한 제약조건만 설정하고 foreign key에 대한 제약조건 바로 설정하지 않았다.
(R2-3) 생성된 테이블에 데이터를 저장해야 한다. 데이터는 csv파일로 주어지며 이를 직접 변형해선 안 된다.
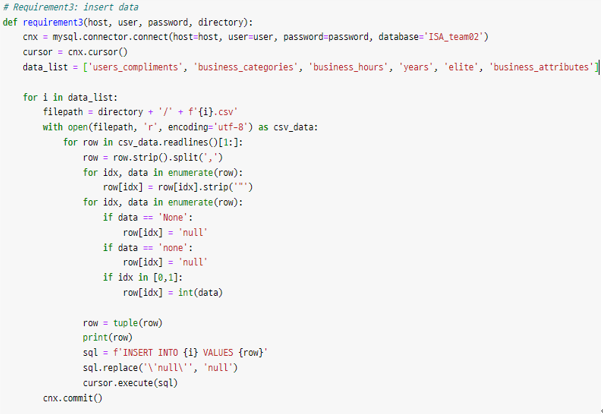
모든 csv파일들을 확인하여서 none값에 대한 확인을 하였고, 총 2개의 csv 파일에 none값이 None, none으로 표현되는 것을 확인할 수 있었다. 또한 숫자형 데이터의 경우 csv파일을 불러오고 나서 문자형으로 입력되는 것을 방지하기 위해서 int()함수를 다시 적용해주는데, int()함수가 적용되는 column의 index에 따라서 코드 밑에서 8번 째 줄을 바꿔주어야 한다.
(R2-4) 해당 데이터베이스 스키마에foreign key 조건들을 반영해주어야 한다.

테이블들은 모두 primary key와 foreign key에 해당되는 column들이 모두 포함되어 있고, primary key의 경우는 미리 requirement2-2에서 제약조건을 설정해주었다. 나머지 foreign key에 대한 제약조건을 반영해주기 위해 위와 같은 방식으로 ALTER를 이용하여 지정하였다.
(R2-5) R2-1 ~ R2-4로 구축한 DB와 데이터들을 분석하여 사이트 A를 이용하는 잠재적인 고객들이 검색할 만한 query (질의)를 제시해보고 해당 query를 통해 획득할 데이터를 view로 생성하라.
사이트 A를 이용하는 잠재적인 고객들에 대해 우리는 하나의 가정을 통해서 View를 생성하였다. 가정은 다음과 같다.
가정 : 사이트 A를 이용하는 고객들은 여름이 다가옴에 따라 휴양차 글렌데일로 놀러가고자 하는 사람들이다. 글렌데일 근처에서 호텔을 구하고 싶은데, 어느정도 평가가 좋은 호텔을 구하고자 한다. 또 필수적인 조건을 호텔에서 와이파이를 무료로 이용하고 싶다. 이러한 조건들을 view를 통해서 확인하고 비교해보고자 한다.


출처
[1] 박인범 교수, 정보시스템 분석 및 설계, 프로젝트 문제
728x90
'Research' 카테고리의 다른 글
| GAN: 존재하지 않는 이미지를 어떻게 생성할까? (1) | 2022.09.30 |
|---|---|
| [CNN/Transfer learning] 타코, 브리또 사진 분류하기 (1) | 2022.09.30 |
| DB 설계 및 HeidiSQL을 이용한 DB 구현 PART3: SQL 개념 및 예문 (1) | 2022.09.30 |
| DB 설계 및 HeidiSQL을 이용한 DB 구현 PART2: ERD 개념 (0) | 2022.09.30 |
| DB 설계 및 HeidiSQL을 이용한 DB 구현 PART1: DB 기본 개념 (1) | 2022.09.30 |
'Research' Related Articles
more




Comments