
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 딥러닝
- pytorch
- moirai
- timesfm
- timellm
- queueing theory
- operation management
- 토픽모델링
- 불규칙적 샘플링
- nccl 업그레이드
- ERD
- GaN
- nccl 업데이트
- 분산 학습
- Time Series
- pre-trained llm
- 리뷰
- NTMs
- Transformer
- m/m/s
- 의료정보
- first pg on this rank that detected no heartbeat of its watchdog.
- 패혈증 관련 급성 호흡곤란 증후군
- irregularly sampled time series
- length of stay
- gru-d
- ed boarding
- multi gpu
- nccl 설치
- 대기행렬
- Today
- Total
데알못정을
Multimodal machine learning 본문
1. What is Multimodal Learning?
멀티모달 러닝이란 인간의 "5가지 감각기관"과 같이 multiple modalities로부터 다양한 정보를 처리하고 연결시키는 모델을 만들어서, 인간의 인지적 학습방법과 같이 세계를 이해하는 학습 방법이다.
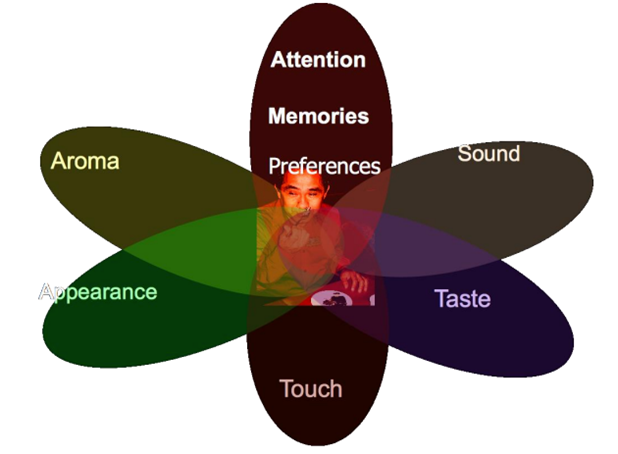
인간의 5가지 감각기관이라 하면 시각, 후각, 미각, 촉각, 청각 등이 있겠지만 머신러닝에 실제로 구현하고자 하는 모달은 시각(사진, 동영상, 글), 청각(음성)에 해당할 수 있다. 즉 multimodal learning에서 다루고자 하는 modal은 아래와 같다.
- Verbal(written or spoken, words, syntax,....)
- Vocal(sounds, para-verbal, prosody, vocal expressions,....)
- Visual(images, videos, eye contact,....)
2. History of Multimodal Applications
멀티모달 연구는 [4]가 등장하면서 시작이 되었다. 사람들은 '가가'라고 말하는 사람의 입술을 보면서 '바바'라는 음절을 들었을 때, 그들은 '다다'라는 다른 음성으로 인식했다. 이 연구의 원래 목적은 시각적 정보와 음성 신호를 같이 활용하여 speech recognition 성능을 향상하기 위한 것이었다.

그림 1에서 x 축은 signal-to-noise ratio로, 수치가 클수록 노이즈가 작다는 것을 의미한다. 그림에서 빨간 선은 audio와 visual 정보를 같이 고려했을 때의 음성인식의 error rate(y축)를 의미하고, 반대로 파란 선은 audio만 고려했을 때의 음성인식의 error rate를 의미한다. 결과를 잘 보면 노이즈가 많아도(signal-to-noise ratio가 작아도) 두 모달을 함께 사용했을 때 경우가 노이즈가 없을 때 audio만 사용한 성능과 비등하다.
이는 하나의 modality가 노이즈가 많은 상황에서(명확한 정보가 없는 상황) 다른 modality를 함께 사용하면 성능을 높일 수 있음을 의미한다. 이는 Multimodal learning의 목적과 필요성으로 연결되었다.
3. Taxonomy: 5 Core challenges
본 논문의 저자는 연구되고 있는 multimodal machine learning을 5가지의 분류로 나누었다.

1) Representation
Raw data를 모델이 잘 처리할 수 있도록 특징 공간에 representation 하는 것은 매우 중요하다. 예를 들어 우리가 흔히 볼 수 있는 이미지의 경우 CNN으로 특징을 capture했다. 자연어의 경우엔 Word2 vec을 사용하여 수치로 표현하기도 했다. 이러한 것처럼 Multimodal에서도 어떻게 다양한 modal들을 서로 같은 공간에 표현할 것인지에 대한 이슈가 있다. Multimodal의 바람직한 representation이라 함은 data spcae에서 유사한 modal은 representation space에서도 유사해야 한다.

Representation은 기존 연구에서 크게 2가지 방식이 존재한다. (a) Joint representation, (b) Coordinated representation

(a) Joint representation
그 중 첫 번째인 Joint representation은 unimodal을 동일한 표현 공간으로 결합하는 방법이다. 각각의 unimodal representation은 동일한 표현 공간으로 결합하는 방법이다. 각각의 unimodal representation은 신경망을 통해 하나의 벡터로 결합된다.
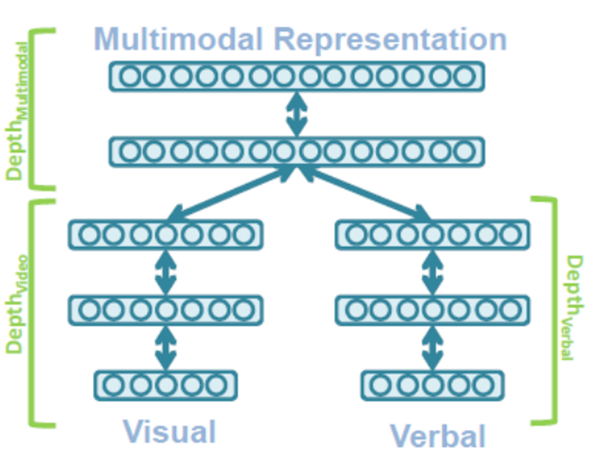
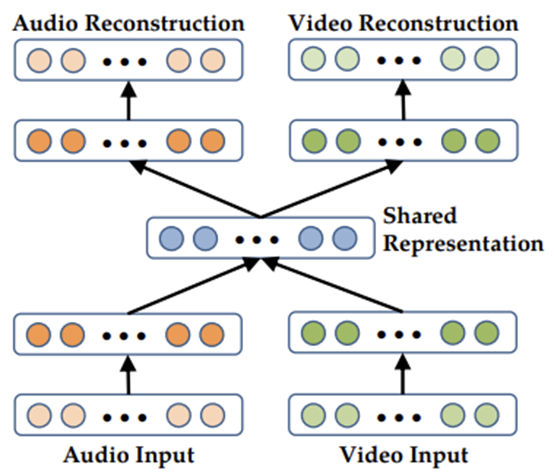
[7] "Multimodal Deep Learning"이라는 논문에서는 Autoencoder 구조를 활용했다. 각 modal은 각각의 encoder를 통해 입력되고 decoder를 통해 복원된다. 이때 encoder와 decoder 사이의 공통 공간을 공유하여 원래 modal의 특성을 살리면서 representation을 수행했다.
(b) Coordinated representation
Coordinated representation은 unimodal을 개별적으로 처리한 후 유사도를 최대화하는 방향으로 학습이 진행된다. 아까 그림 5에서 '~'는 코사인거리 최소화, 상관관계 최대화 등의 방법론이 있다.
[8] 'WSABIE'에서는 'dog'라는 단어와 실제 강아지 사진사이의 거리가 자동차 사진사이의 거리보다 가깝도록 학습을 유도하는 전략을 사용했다. WSABIE는 이러한 접근법의 초기모델로, Linear mapping을 통해 표현된 두 modality 벡터 사이의 코사인 유사도를 계산하였다.
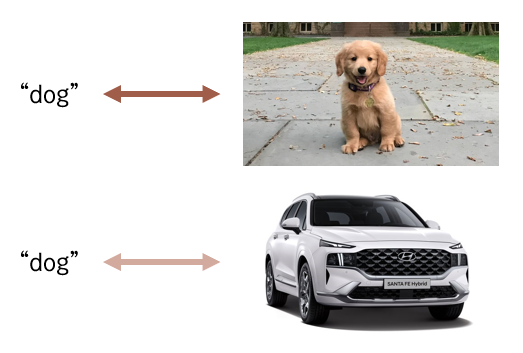
[9] 'Multimodal Vector Space Arithmetic'는 WSABIE 연구의 확장판으로, LSTM과 pairwise ranking loss를 사용함으로써 문장과 이미지 사이의 coordinated representation을 수행했다.

2) Alignment
Multimodal Alignment란 2개 이상의 modality의 구성요소 사이의 대응이나 관계를 찾는 것이다. 처음에는 이 말이 잘 이해가 되지 않았지만 사례를 통해 alignment가 뭘 하려는 작업인지 알 수 있었다.
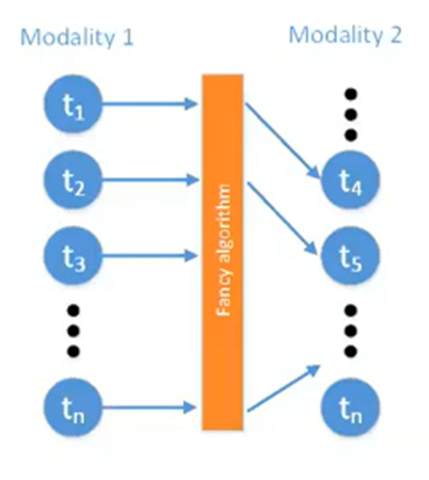
Alignment는 크게 2가지로 나뉜다. 1.Explicit Alignment, 2.Implicit Alignment
1.Explicit Alignment
- The goal is to directly find correspondences between elements of different modalities
Explicit Alignment는 modality 요소들 사이에서 '직접적인' 대응을 찾는 것이다. 예를 들어 김치볶음밥을 만드는 영상(video)를 레시피 스크립트(text)와 대응시키는 작업이 있다.
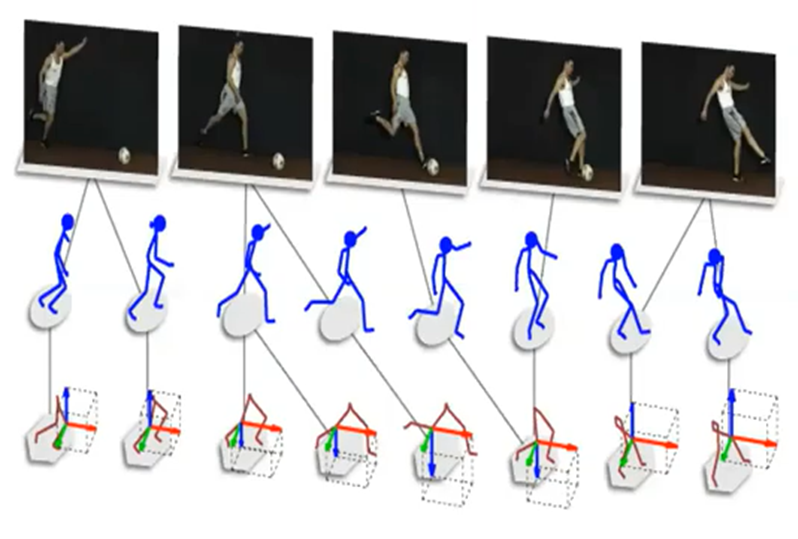
2.Implicit Alignment
- Uses internally latent alignment of modalities in order to better solve a different problem
Implicit Alignment는 modality 요소들 사이에서 '전체적인' 대응을 찾는 것이다. Explicit Alignment를 활용하여 최종 task를 잘 수행할 수 있게 하는 것이 목적이다. 예를 들어 아래 연구 사례를 보자

위 연구에서 빨간색 바운딩 박스에 'person'을 매칭하는 작업은 explicit alignment고, 전체 그림이 'person (who)rides elephant past shop'라는 전체 text와 매칭된다. 이는 결과론적으로 implicit alignment라 이해하였다.
3) Translation
Multimodal Translation은 한 modality를 다른 modality로 바꾸는 것을 의미한다. 이 방법은 크게 두가지 방식이 존재한다.
(a) Example-based, (b) Generative
(a) Example-based
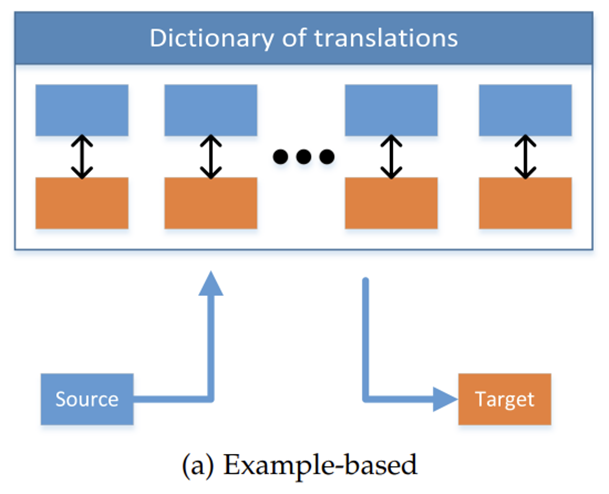
example-based는 source modal과 target modal의 dictionary가 사전에 정의되어 있어서 검색 방식으로 활용하는 방법이다.
즉 Dictionary sample로부터 source modal과 가장 비슷한 target modal을 찾는 것인데, 이 방식은 또 두 가지로 나뉜다.
(a) - 1 Retrieval-based models, (a) - 2 Combination-based models
(a) - 1 Retrieval-based models
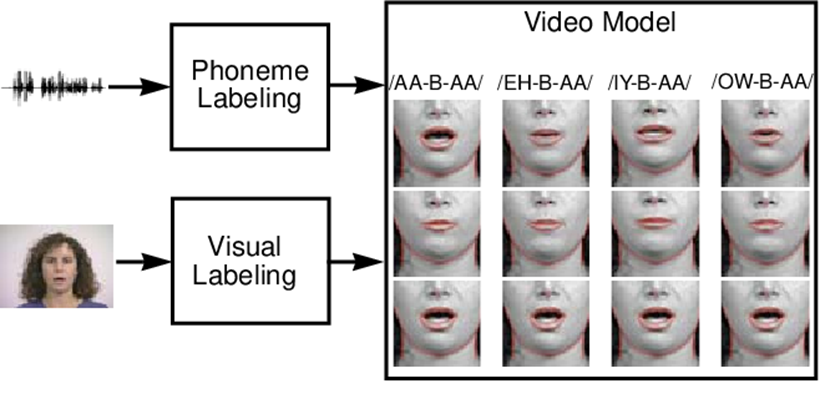
이 연구[11]에서는 Phoneme labeling과 Visual labeling의 dictionary가 있었고, 이를 통해 아예 다른 새로운 오디오 트랙에 포함된 단어를 말하는 사람의 영상으로 합성했다. 이는 실제로 딥페이크 기술의 초기 시도로 평가되었다.
(a) - 2 Combination-based models
이 방식은 (a) -1 방식에서 조금 더 발전된 방식으로, 다른 modality들의 example을 의미 있게 결합한다.

이 연구[12]에서는 Input image(배)와 비슷한 K개의 이미지를 dictionary로부터 가져와 그들의 캡션을 추출하고, 가장 적합한 text를 생성(target sentence)했다.
전체적으로 봤을 때 이런 example based 방식의 문제점은 전적으로 딕셔너리에 의존한다는 것이다. 이는 사례의 갯수가 많아지면 많아질수록 매우 비현실적이며 비효율적인 방식이다.
(b) Generative
Generative translation은 Unimodal source instance가 주어졌을 때 multimodal translation을 수행하는 방식이다.(language generation, speech&sound generation, photo-realistic image generation)
아까는 사전이 정의가 되어있었는데 여기서는 사전 자체를 모델링하는 것이다. 따라서 example based의 단점을 보완할 수 있다.
대표적으로 Encoder-Decoder 방식이 있다. 이는 Source instance를 latent로 표현한 후 decoder가 target modality를 생성하는 형태이다. 매우 직관적이다.

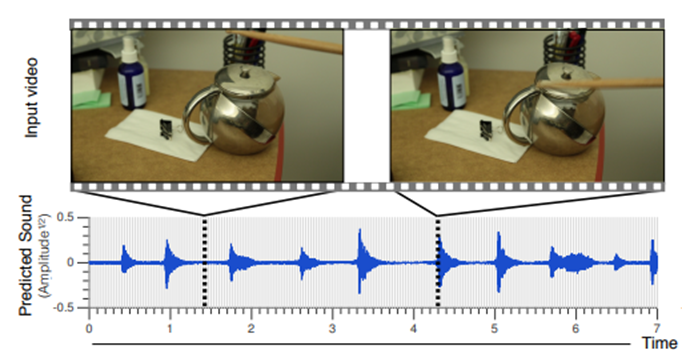
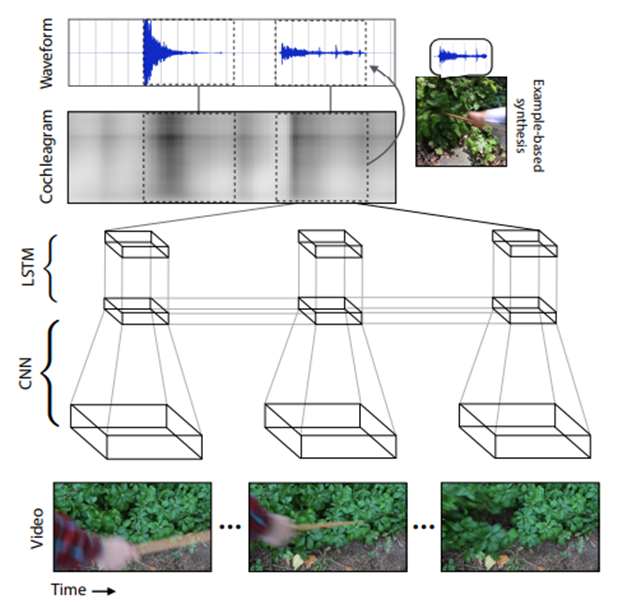
이 연구[13]는 막대기로 주전자를 때리는 영상인데 소리가 없는 영상을 입력으로 넣어 이를 음성 신호로 translation하는 것이 주목적이다. 사전이 미리 정의되지 않았지만 LSTM과 CNN을 사용하여 dictionary자체를 모델링했다고 볼 수 있다.
4) Fusion
Multimodal Fusion은 예측 단계(분류, 회귀)에서 다양한 modality의 정보를 결합하는 것이다.
- 모델을 더욱 robust하게 만들어 주며
- Unimodality에서 자체적으로 볼 수 없는 보충적 정보를 얻을 수 있음
- 하나의 modality가 missing인 상황에서도 정상 작동 가능(감성 인식 문제에서 음성 없이 시각적으로 표정만 보더라도 감정을 예측할 수 있는 것과 비슷)
Fusion도 역시 Model-Agnostic Approaches와 Model-Based Approaches가 존재한다.
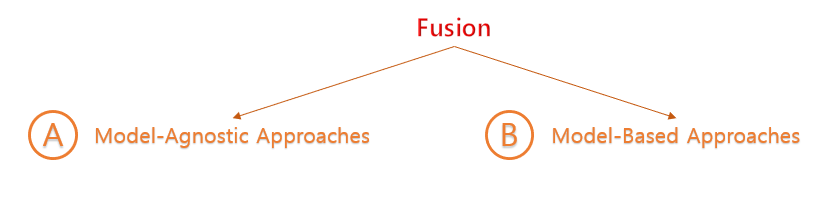
A. Model-Agnostic Approaches
- Early fusion: 두 modality를 단순히 concatenate 하여 특징을 통합하는 방식
- Late fusion: modality가 각각 model을 만든 후에 fusion mechanism을 통해 특징을 통합하는 방식
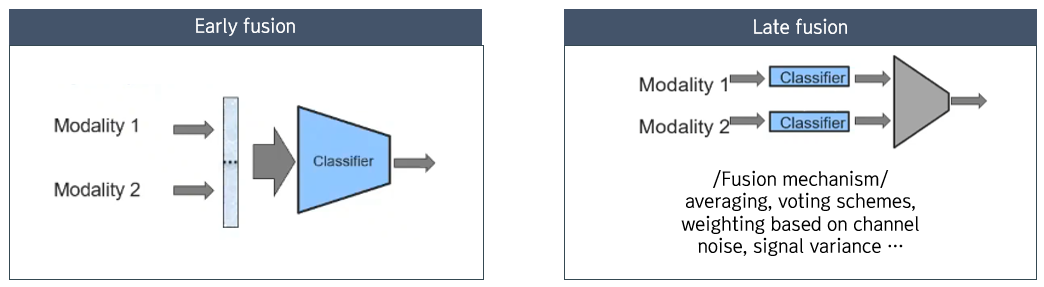
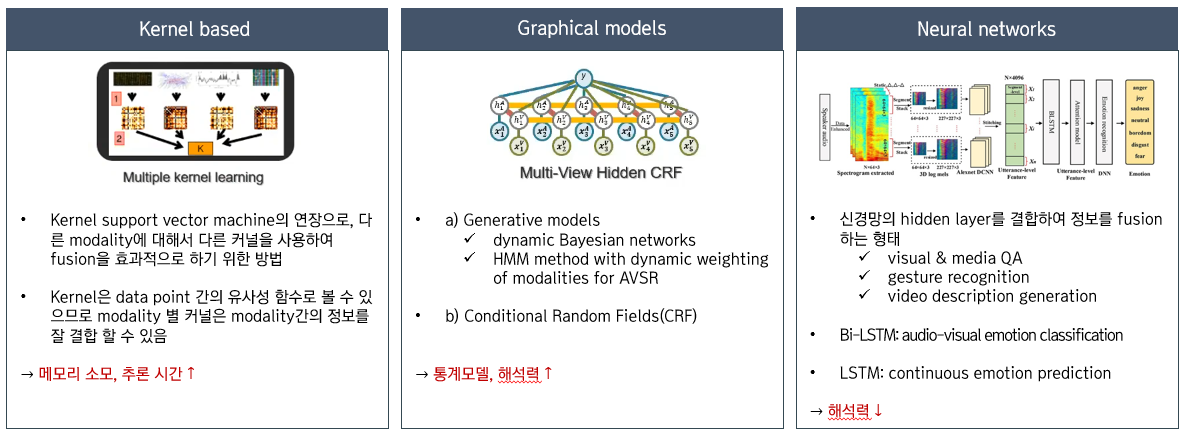
5) Co-learning
Multimodal Co-learning이란 Modality 사이에 Knowledge를 전이하는 것이다. 자원이 풍부한 modality의 지식을 활용하여 자원이 부족한 modality의 모델링을 지원하는 형태이다. 이때 자원이 부족한 modality라 함은 데이터의 부족, 많은 노이즈 함유, 신뢰할 수 없는 label 등이 있는 데이터를 의미한다. 자원이 풍부한 modality는 학습 과정에서만 활용되며 추론 과정에는 사용되지 않는다.
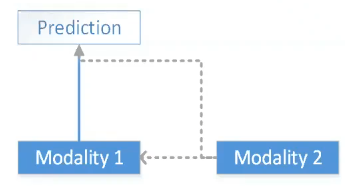
Co-learning은 (a) Parallel, (b)None-parallel 방식이 있다.
(a) Parallel
(a) Parallel은 한 modality의 관측치가 다른 modality의 관측치와 1대 1 대응되는 데이터세트가 있는 상황이다. 비디오와 음성 샘플이 동일한 스피커에서 나온 시청각 음성 데이터세트와 같이 동시에 수집된 데이터이다.
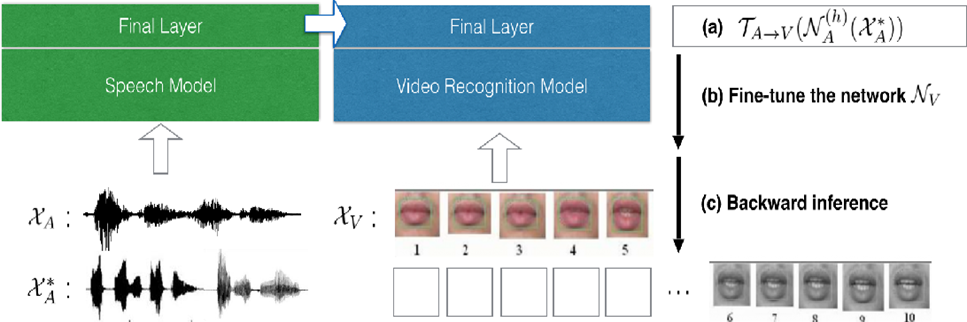
아래 연구[14]는 Audio와 Lip image가 pair를 이루고 있는 데이터 셋을 통해 표현을 학습하고, 나중에 새로운 Audio data*가 입력되었을 때 그와 대응되는 Lip image 없이 새로운 Lip image를 생성한 사례이다.
(b) None-parallel
(b)는 한 modality의 관측치가 다른 modality의 관측치와 1대 1 대응되는 데이터세트가 없는 상황이다. 아래 연구[15]는 비록 이미지와 word 사이 정확한 pair관계가 아니었지만 두 모달을 함께 사용하여 Zero-shot이 가능하도록 했다.
이 연구(DeviSE)는 CNN feature와 Word2vec 임베딩을 조정함으로써 Visual representation을 향상시켰다. 이미지의 특징을 잘 표현한다는 것을 증명하는 '오류'가 도출된 것이 특징이다.
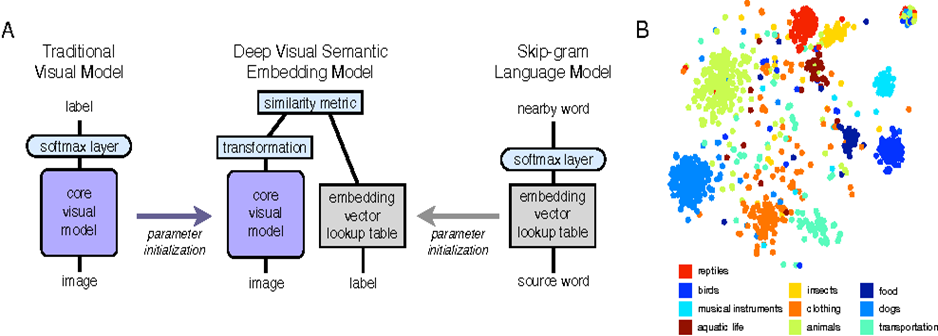
DeviSE는 모델을 훈련시킨 후 아예 새로운 호랑이 이미지와 호랑이를 설명하는 side-information을 함께 입력하여 비록 한 번도 호랑이를 본 적이 없지만 호랑이에 대한 의미를 내포하는 임베딩 값을 도출하였다.(zero-shot learning이 가능) 훈련과정에서 한 번도 본 적이 없는 데이터가 입력이 되더라도 임베딩 공간 상 클래스 간의 관계를 통해 올바른 클래스를 예측할 수 있었던 연구이다.
4. Conclusion
- Multimodal machine learning을 5가지 Task로 분류하고, 관련 연구를 소개하였음
- 특히 최근에는 representation과 translation이 많이 연구되고 있음을 알 수 있었음
- Multimodal machine learning에 대한 교과서를 제시
- 논문을 공부하는 과정에서 CMU(Carnegie Mellon University)의 multimodal 강의를 참고했는데, 이 강의에서는 본 논문을 중심으로 커리큘럼을 구성했음(저자가 강의하긴 했지만)
- Representation과 fusion의 차이점이 무엇인지 그 분류 경계가 모호하다는 생각이 들었음(혹시 좋은 아이디어가 있다면 댓글로 같이 논의해봅시다!!)
- Multimodal learning은 하나의 데이터 양식이 아니라 여러 양식을 함께 고려하여 의사결정을 하는 것이 특징임
- A라는 나라의 수화 이미지를 B라는 나라의 수화 이미지로 변환하는 Multimodal Translation
- Multimodal learning을 통해 사람을 위한 인공지능이 많이 연구될 것이라 생각함
5. Reference
- 관련문서
- [1] Baltrušaitis, Tadas, Chaitanya Ahuja, and Louis-Philippe Morency. "Multimodal machine learning: A survey and taxonomy." IEEE transactions on pattern analysis and machine intelligence 41.2 (2018): 423-443.
- [2] B. P. Yuhas, M. H. Goldstein, and T. J. Sejnowski, “Integration of Acoustic and Visual Speech Signals Using Neural Networks,” IEEE Communications Magazine, 1989.
- [3] J. Ngiam, A. Khosla, M. Kim, J. Nam, H. Lee, and A. Y. Ng, “Multimodal Deep Learning,” ICML, 2011.
- [4] B. P. Yuhas, M. H. Goldstein, and T. J. Sejnowski, “Integration of Acoustic and Visual Speech Signals Using Neural Networks,” IEEE Communications Magazine, 1989
- [5] https://engineering.mercari.com/en/blog/entry/20210623-5-core-challenges-in-multimodal-machine-learning/
- [6] https://www.youtube.com/watch?v=VIq5r7mCAyw&list=PL-Fhd_vrvisNup9YQs_TdLW7DQz-lda0G&index=1
- [7] J. Ngiam, A. Khosla, M. Kim, J. Nam, H. Lee, and A. Y. Ng, “Multimodal Deep Learning,” ICML, 2011.
- [8] J. Weston, S. Bengio, and N. Usunier, “WSABIE: Scaling up to large vocabulary image annotation,” in IJCAI, 2011.
- [9] R. Kiros, R. Salakhutdinov, and R. S. Zemel, “Unifying VisualSemantic Embeddings with Multimodal Neural Language Models,” 2014.
- [10] A. Karpathy and L. Fei-Fei, “Deep visual-semantic alignments for generating image descriptions,” in CVPR, 2015.
- [11] Bregler, Christoph et al. “Video Rewrite: driving visual speech with audio.” Proceedings of the 24th annual conference on Computer graphics and interactive techniques (1997): n. pag
- [12] A. Gupta, Y. Verma, and C. V. Jawahar, “Choosing Linguistics over Vision to Describe Images,” in AAAI, 2012.
- [13] A. Owens, P. Isola, J. McDermott, A. Torralba, E. H. Adelson, and W. T. Freeman, “Visually Indicated Sounds,” in CVPR, 2016.
- [14] S. Moon, S. Kim, and H. Wang, “Multimodal Transfer Deep Learning for Audio-Visual Recognition,” NIPS Workshops, 2015.
- [15] A. Frome, G. Corrado, and J. Shlens, “DeViSE: A deep visual semantic embedding model,” NIPS, 2013.
'Research' 카테고리의 다른 글
| About Circulatory Failure (0) | 2023.09.20 |
|---|---|
| Domain Adaptation in Computer Vision: Everything You Need to Know - Korean Version (0) | 2023.08.06 |
| GAN: 존재하지 않는 이미지를 어떻게 생성할까? (1) | 2022.09.30 |
| [CNN/Transfer learning] 타코, 브리또 사진 분류하기 (1) | 2022.09.30 |
| DB 설계 및 HeidiSQL을 이용한 DB 구현 PART4: DB 제작 하기 (1) | 2022.09.30 |



