
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- 딥러닝
- NTMs
- multi gpu
- Time Series
- ERD
- 인과추론
- 불규칙적 샘플링
- 인과추론 의료
- 리뷰
- causal machine learning
- first pg on this rank that detected no heartbeat of its watchdog.
- GaN
- 의료정보
- 분산 학습
- 의료
- nccl 업그레이드
- causal reasoning
- gru-d
- causal forest
- 토픽모델링
- machine learning
- pytorch
- causal inference
- causal ml
- Transformer
- causal transformer
- doubleml
- irregularly sampled time series
- netflix thumbnail
- nccl 업데이트
- Today
- Total
데알못정을
[연구 분야 조사] Causal machine learning for predicting treatment outcomes 1편 본문
[연구 분야 조사] Causal machine learning for predicting treatment outcomes 1편
쩡을이 2025. 4. 8. 22:10본 포스팅은 Feuerriegel, Stefan, et al. "Causal machine learning for predicting treatment outcomes." Nature Medicine 30.4 (2024): 958-968.를 읽고 정리한 글임을 밝힙니다.
causal ML in medicine은 치료로 인한 환자 결과의 변화와 같은 인과 관계를 예측하는 것을 목표로 한다. causal ML은 RCT(Randomized Controlled Trials)를 통해 얻은 실험 데이터와 임상 등록, 전자 건강 기록 및 기타 RWD(Real-World Data) 소스에서 얻은 관찰 데이터를 모두 사용하여 치료 효과를 추정하고 임상적 증거를 생성하는 데 사용될 수 있다.
causal ML의 핵심 강점은 개별화된 치료 효과와 다양한 치료 시나리오에서 잠재적인 환자 결과 (예: 생존, 재입원, 삶의 질)에 대한 개인 맞춤형 예측을 가능하게 한다는 것이다. 이를 통해 치료가 효과적인지 또는 해로운지에 대한 세부적인 이해를 제공하여 환자 치료 의사 결정을 개별 환자 프로필에 맞게 개인화할 수 있다.
그러나, causal inference는 검증할 수 없는 공식적인 가정에 기초하므로 신중하게 사용해야한다. 따라서 본 논문에서는 casual ML이 traditional ML과 어떤 부분이 다른지 설명하고, 임상에서 사용하기 위한 단계와 필수 구성요소를 논의한다. 또한 논문에서는 causal ML의 안정적인 사용과 임상으로의 효과적인 전환을 위한 권장사항을 제공한다.
Causal ML in medicine
의학 분야에서 causal ML은 데이터로부터 개별화된 치료 효과를 추정할 수 있는 여러 기회를 제공하며, 궁극적으로 더 나은 치료 개인화에 기여할 수 있다.
첫째, 환자 수준에서 causal ML은 환자 공변량(변수)을 포함하는 고차원적이고 비정형화된 데이터를 처리하여 이미지, 텍스트, 시계열 데이터뿐만 아니라 유전 데이터까지 포함하는 다중 모드 데이터 세트로부터 치료 효과를 추정할 수 있다. 예를 들어, 컴퓨터 단층 촬영 스캔 또는 전체 전자의무기록으로부터 치료 효과를 추정할 수 있다.
둘째, 결과 수준에서 causal ML은 하위 모집단에 대한 치료 효과를 개인별로 추정하거나 개별 환자의 결과를 예측하는 데 도움을 줄 수 있다. 예를 들어, 약물 대사의 개인차가 일부 환자에게는 심각한 부작용을 일으키지만 다른 환자에게는 생명을 구할 수도 있으므로, causal ML 접근 방식은 이러한 차이를 학습하여 개인 맞춤형 치료 전략을 설계하는 데 도움을 줄 수 있다.
셋째, 치료 수준에서 causal ML은 데이터 기반 방식으로 환자 간 치료 효과의 이질성을 추정하여 어떤 환자 하위 그룹에게 치료가 효과적인지 식별하는 데 효과적일 수 있다.
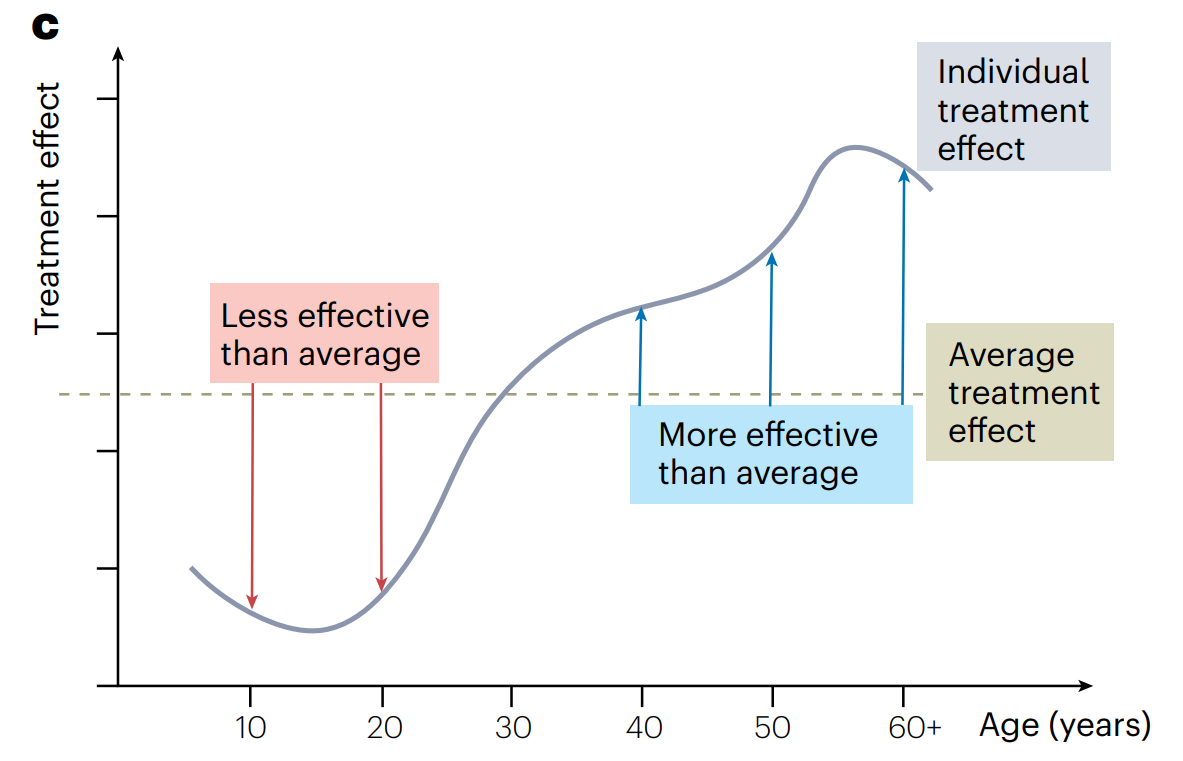
이러한 이점에도 불구하고, causal ML은 맞춤형 방법이 필요한 뚜렷한 과제를 안고 있다. 게다가 이 방법의 적절한 응용을 하기위해서는 causal ML이 traditional ML과 어떻게 다른지에 대한 이해가 필요하다.
When should I use causal ML?
치료 효과를 추정하기 위한 causal ML은 기존의 predictive ML과는 다르다. 직관적으로, 기존 ML은 결과 예측을 목표로 하는 반면, causal ML은 치료로 인한 결과 변화를 정량화하여 치료 효과를 추정할 수 있도록 한다.
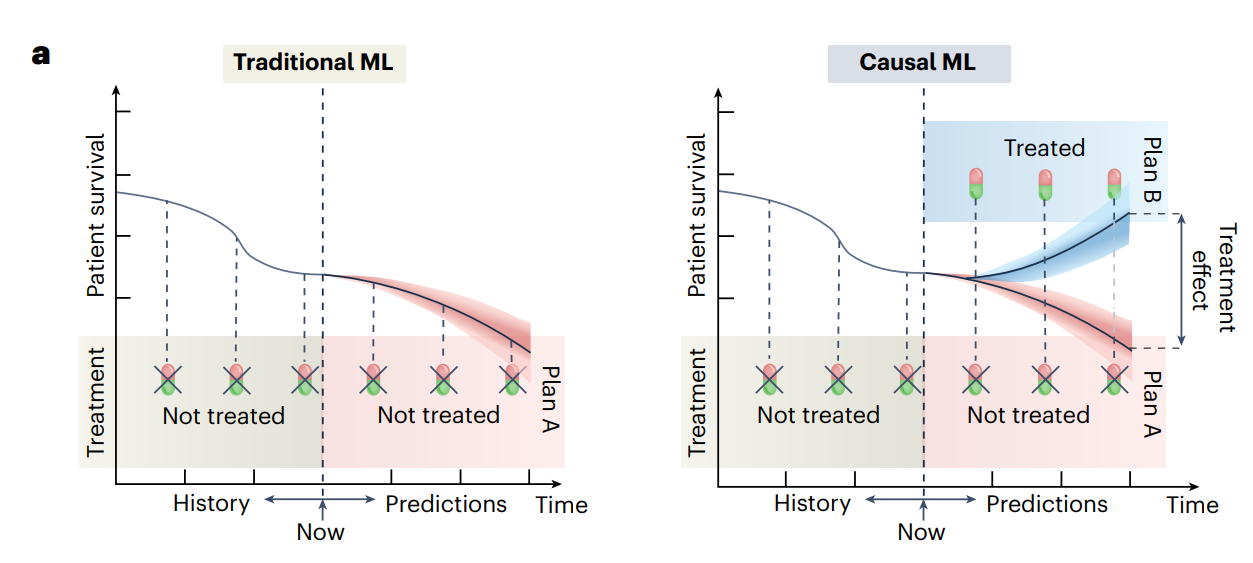
tradition ML의 사용 $\rightarrow$ "어떤 치료 계획이 최고인지 제시하 않고 어떤 환자가 위험한지 이해하기 위해 당뇨병 발병 확률을 예측 하는 것"
causal ML의 사용 $\rightarrow$ "만약에" 질문에 대한 해답을 찾는 것을 목표로 한다. 예를 들어, causal ML은 환자가 antidiabetic drug (항당뇨병제)를 투여 받을 경우 당뇨병 발병 위험이 어떻게 변화하는지 추정하여 해당 약물 투여 여부에 대한 결정을 내릴 수 있도록 한다. (다양한 치료법에 대한 반응으로 나타나는 잠재적인 환자 결과를 예측할 수 있음 $rightarrow$ 의료 종사자들이 생존 가능성을 최대화하거나 생존 기간을 최장으로 늘릴 수 있는 치료 계획을 선택하는 데 도움을 줄 수 있음)
치료의 효과를 밝히는 통계적 접근법 역시 존재해 왔다. casual ML도 이들의 목적과 동일한 목표를 두고 개발되었지만, 추정 전략에 차이가 있다.
기존 통계 방식은 환자의 특징과 결과사이의 연관성에 대해 선형 의존성과 같은 특정 형태를 가정하는 경우가 많다. 하지만 EHR과 같은 고차원 데이터에서는 이러한 가정을 충족하기 어렵고, 모델이 부정확해질 수 있다. causal ML은 이러한 엄격한 가정을 덜 요구하는 모델을 사용하여 복잡한 질병 역학 관계와 인간의 병태생리, 약리학적 특성을 더 잘 포착할 수 있다.
하지만 causal ML은 일반적으로 더 큰 표본 크기를 필요로 한다는 단점이 있다.
The fundamental problem of causal inference
인과 추론은 단순히 상관관계를 파악하는 것을 넘어, 특정 원인이 결과에 미치는 영향을 정확히 파악하는 것을 목표로 한다. 하지만 실제 데이터에서는 모든 상황을 완벽하게 관찰할 수 없기 때문에 어려움이 발생한다.
근본적인 문제로는 개별 환자에 대한 치료 효과를 정확히 파악하는 것이 불가능 하다는 것이다. 왜냐하면 각 환자는 실제로 받은 치료에 대한 결과 (factual outcome)만을 관찰할 수 있고, 만약 다른 치료를 받았더라면 나타났을 결과 (counterfactual outcoem)은 관찰할 수 없기 때문이다.
예를 들어, 어떤 환자가 A라는 치료를 받고 회복되었다면, A 치료를 받지 않았을 경우의 결과는 알 수 없다. 반대로 B라는 치료를 받지 않고 회복되지 않았다면 B라는 치료를 받았을 때의 결과를 알 수 없다. 이는 동시에 두 가지 상황을 모두 경험할 수 없기 때문에 발생하는 문제이다.
이러한 이유로, 치료 효과를 추정하거나 다른 인과 관계를 파악하기 위해서는 추가적인 방법과 가정이 필요하다. 관찰되지 않은 반사실적 결과를 추론해야 하므로, 전통적인 예측 모델과는 다른 접근 방식이 요구한다.
추가적인 가정으로 많이 사용하는 것 $\rightarrow$ "측정되지 않은 교란(confounding) 요인이 없다". 즉, 치료 결정과 후속 환자 결과 모두에 영향을 미치는 관찰되지 않은 요인이 없어야 한다는 가정
만약 측정되지않은 교란 변수 (confounding) 가 존재한다면, 추정된 치료 효과는 confounding bias로 인해 부정확할 수 있다.
잘 이해가 안되서 chatgpt 예시:
특정 질병에 대한 치료 효과를 분석할 때, 환자의 '건강에 대한 동기'라는 요인을 고려하지 못하는 경우를 생각해볼 수 있습니다.
건강에 대한 동기가 높은 환자는 적극적으로 치료를 받고, 건강 관리에도 힘쓰기 때문에 치료 결과가 좋을 가능성이 높습니다.
반면, 건강에 대한 동기가 낮은 환자는 치료를 소극적으로 받거나 건강 관리를 소홀히 할 수 있어 치료 결과가 좋지 않을 수 있습니다.
이때, '건강에 대한 동기'가 측정되지 않았다면, 치료 효과를 과대 또는 과소평가할 수 있습니다. 즉, 실제로 치료가 효과가 없을 수 있지만, 건강에 대한 동기가 높은 환자들이 자발적으로 치료를 잘 받아 효과가 있는 것처럼 보일 수 있습니다.
$\rightarrow$ 꽤나 중요한데..?
또한 치료 효과를 추정하기 위해서는 근본적인 인과 관계를 모델링하여 치료, 결과 및 환자 특성 간의 의존성 구조를 설명해야한다.
예를 들어, 의사가 금연을 권고하고 당뇨병 위험을 예측해야 하는 고도 비만 환자를 생각해 보겠다. 기존 머신러닝 문헌에서는 금연 여부에 따른 당뇨병 위험을 예측하기 위해 체질량 지수와 흡연 습관을 모두 사용하도록 제안한다. 그러나 이러한 접근 방식은 금연이 환자의 체질량 지수 또한 변화시킬 수 있다는 점을 간과한다. 이 문제를 해결하려면 인과적 프레임워크에 머신러닝을 포함해야한다.
잘 이해가 안되서 ChatGPT한테 질문 : 그러니까, 기존에 알려진 인과 관계를 정리하고, 이를 치료 효과 추정에 반영해야 한다는건가요? 어떻게 하는건가요?

$\rightarrow$ 너무 모호하다.... 그래프 ??
The causal ML workflow
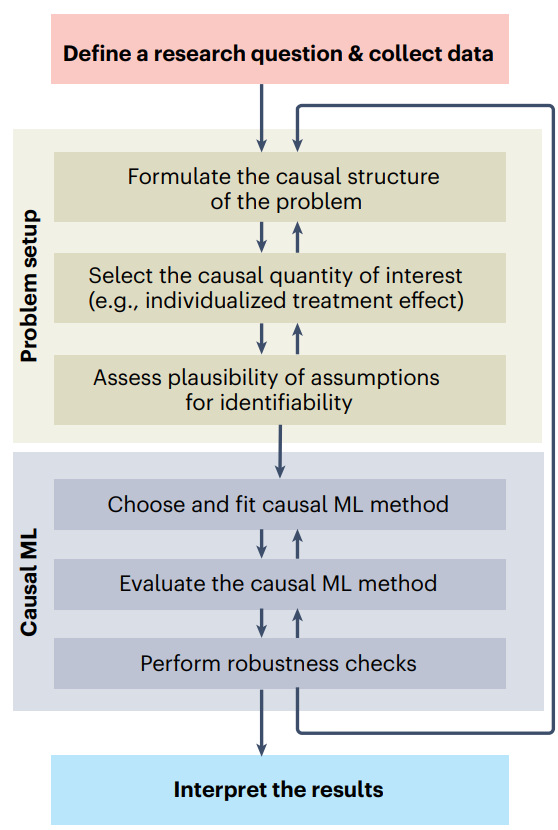
1. Formulate the causal structure of the problem
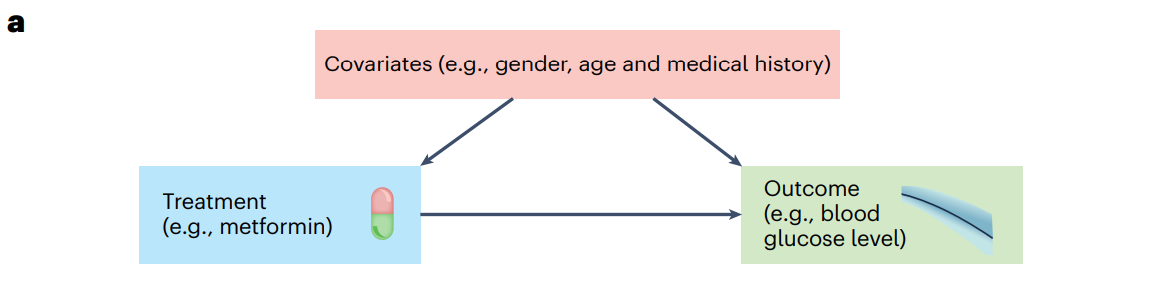
치료의 효과성을 평가하기 위해 변수에 대한 정보가 필수적이다. 변수에 대한 정보로는 treatment of interest (분석하고자 하는 치료), 관측된 환자의 최종 결과, 환자의 특징(환자와 관련된 변수로, 나이, 성별, 의료 기록)
예를들어, 암 치료의 경우, 분석하고자 하는 치료 = 화학 요법의 종류, 환자의 최종 결과 = 암 종양의 크기, 환자의 특징 = 이전 병력이 됨
일반적인 설정에서, 변수들은 아래 그림의 causal graph에서 보이는 것처럼 서로에게 영향을 줄 수 있다.
변수들의 경우 관측적으로 얻어진 데이터일 수도 있고, 실험적(무작위대조 시험 RCT) 으로 얻어진 데이터일 수도 있다.
관측적으로 얻어진 데이터에는 EHR이 포함되고, 이 기록에 있는 treatment는 환자의 특징에 따라 알려지지 않은 절차를 통해 할당되어진다. 예를 들어, 매우 심각한 병이 있는환자는 공격적인 치료를 받는 경향이 있고, 이는 환자의 특징이 treatment groups마다 다르다는 것을 암시한다.
하지만 RCT의 경우 치료법이 무작위로 환자에게 할당되므로, 치료 그룹 간의 환자 특성이 유사하다. 이는 치료 효과를 더 객관적으로 평가할 수 있게한다.
성향점수: 환자의 공변량(나이, 성별, 병력 등)이 주어졌을 때 특정 치료를 받을 확률. 즉, 환자의 특성을 고려했을 때 어떤 치료를 받을 가능성이 높은지를 나타내는 지표
EHR 데이터에서의 성향 점수: 치료 할당이 환자 특성에 따라 결정되기 때문에 성향 점수는 알 수 없다. 따라서, 인과추론을 위해 성향 점수를 추정해야 한다. 성향 점수를 추정하는 것은 환자 모집단의 차이를 보정하는 데 중요하다.
무작위대조 시험에서의 성향 점수: 치료가 무작위로 할당되기 때문에 성향 점수는 알려져 있다. 예를 들어, 두 개의 치료 그룹이 있고 각 그룹에 환자가 무작위로 50%씩 배정되었다면, 성향 점수는 50%이다.
2. Select the causal quantity of interest
(원문 번역)
치료 반응과 같은 causal quantity은 일반적으로 'potential outcomes framework'에 기반하여 공식화된다. 이 프레임워크는 특정 치료법이 투여되었을 경우 가상적으로 관찰될 환자의 결과인 잠재적 결과를 개념화한다. 그런 다음 실제 적용 분야에 따라 다양한 causal quantity가 중요할 수 있다. 여기에는 다양한 치료법 하에서 두 잠재적 결과의 예상되는 차이를 정량화하는 치료 효과가 포함된다. 일반적인 치료 효과 선택은 두 가지 차원(그림 3b)을 따라 느슨하게 그룹화할 수 있다. 효과 이질성의 정도와 치료 유형이다. 특정 치료 효과를 선택함으로써 소위 추정량(estimand)을 정의하는데, 이는 인과 추론 ML 방법으로 예측해야 하는 causal quantity이다.
(쉬운 설명)
[치료 효과는 '가정'을 기반으로 한다.]
환자에게 어떤 치료를 했을 때 결과가 달라지는지 알고 싶은데, "한 사람에게 두 가지 치료를 동시에 해볼 수는 없다"는 점이 문제이다. 그래서 우리가 쓰는 개념이 바로 잠재적 결과 (potential outcomes) 이다.
$Y(1)$: A 치료를 받았을 때의 환자 결과 / $Y(0)$: 치료를 받지 않았을 때의 결과
실제로는 둘 중 하나만 관측 가능하고, 나머지는 가상의 값

[상황에 따라 알고 싶은 "치료 효과"는 달라질 수 있다.]
어떤 경우에는 전체 평균이 중요하고, 어떤 경우에는 개별 환자에 대한 맞춤형 예측이 중요하다.
| 유형 | 설명 | 예시 |
| Average Treatment Effect (ATE) | 전체 평균 치료 효과 | 모든 환자에게 A 약이 효과가 있는가? |
| Averge Treatment effect on Treated (ATT) | 실제로 받은 사람에게만 | A 약을 받은 사람들에게 효과가 있었나 |
| Conditional ATE (CATE) | 조건부 평균 $\rightarrow$ 개인화 | 고혈압 + 당뇨 환자에게만 A약이 효과가 있는가 |
| Individual Treatment Effect (ITE) | 한 사람의 치료 효과 | 이 환자에게 A 약이 효과가 있을까? |
ATE는 집단 전체의 평균 효과만 보여주기 때문에, 어떤 사람에게는 효과가 없거나, 심지어 해로울 수도 있는데 이런 개인차는 ATE에 숨겨져 있을 수 있다. 그래서 의료처럼 개별환자의 반응이 중요한 분야에서는 CATE/ITE 같은 세분화된 추정이 훨씬 더 중요하다.
CATE는 임상 의사결정에 직접적으로 연결된다. "이 치료를 모든 사람에게 할지 말지"가 아니라, "이 환자에게 이 약이 필요할까?" 라는 질문에 답하기 위해서는 CATE 추정이 필수이다.
[이렇게 알고 싶은 'causal quantity'를 정하는 걸 estimand 라고 한다.]
Estimand는 '내가 추정하려는 인과적 목표"이다. Causal ML은 이 estimand를 추정하는 데 쓰이는 머신러닝 도구이다.
[Treatment type]
여기서는 치료 변수의 유형을 이분형, 연속형으로 구분하고, 각 유형의 특징을 설명한다.
이분형 치료 (Binary Treatment)
- 정의: 치료 변수가 두 가지 범주로만 나뉘는 경우를 의미. 예를 들어, 치료를 할지 안 할지와 같이 '예/아니오'로 답할 수 있는 질문에 해당
- 예시: 특정 약물을 투여할지 여부, 특정 수술을 시행할지 여부 등이 있다.
연속형 치료 (Continuous Treatment)
- 정의: 치료 변수가 특정 범위 내에서 다양한 값을 가질 수 있는 경우를 의미한다. 즉, 치료의 강도, 복용량, 노출 정도 등을 자유롭게 선택할 수 있다.
- 예시: 방사선 치료에서 방사선량은 암의 종류와 환자의 특성에 따라 다양하게 결정될 수 있다.
Dose-Response Curve: 연속형 치료에서는 치료 효과를 나타내는 지표로 Dose-Response Curve가 활용됨
Dose-Response Curve 은 치료 용량(dose)과 그에 따른 효과(response) 사이의 관계를 그래프로 나타낸 것이다. 이를 통해 특정 용량에서 최대 효과를 얻을 수 있는지, 또는 특정 용량 이상에서는 효과가 미미하거나 오히려 부작용이 증가하는지 등을 파악할 수 있다.

[Individual patient outcomes]
치료 효과를 추정하는것과 환자별 결과 자체를 예측하는 것은 다르다.
Treatment effect: "A약을 먹으면 평균적으로 사망률이 5% 줄어듭니다."
Potential outcome: "A약을 먹으면 사망률이 15%, 안먹으면 20%입니다." $\rightarrow$ 의사는 더 구체적인 의사결정이 가능
Potential outcome은 두 값(factual, counterfactual)을 모두 예측 해야하기 때문에 모델이 더 복잡하다. 실무에서는 ATE나 CATE만으로도 충분하면 그것만 추정한다.
3. Assess the plausibility of assumptions for identifiability (중요)
여기서는 치료 효과를 믿을 만하게 추정하려면 어떤 가정을 전체로 해야하는가를 다루고 있다. "관측된 데이터만으로 치료 효과를 추정할 수 있을까?" 대부분의 경우, 그냥 관측 데이터만 가지고는 불가능하다. 왜냐하면, 인과추론은 "내가 하지 않은 선택을 했을 때 결과가 어땠을까?"를 추정하는 것이기 때문이다. 즉, 가상의 결과가 필요하다. 그런데 이건 관측되지 않는다. 그래서... 치료 효과를 신뢰할 수 있게 추정하려면, 몇 가지 중요한 가정 (assumption)이 필요하다.
반드시 필요한 3가지 가정
| 가정 | 뜻 | 왜 필요한가? |
| SUTVA (일관성 & 비간섭) | '한 사람의 치료가 다른 사람의 결과에 영향을 주면 안됨' | 혼선 없이 개별 효과를 구분하려면 필요 |
| Positivitiy (양의 확률) | '모든 유형의 사람에게 두 치료 모두 받을 가능성이 있어야 함' | 두 집단을 비교하려면 둘 다 관측돼야 함 |
| Unconfoundedness (비교를 방해하는 숨은 요인이 없음) | '관측된 변수만으로 치료 결정이 설명돼야 함' | 숨은 요인이 있으면 결과가 왜곡됨 |
📌 1. SUTVA – 일관성과 비간섭
이 환자가 A약을 먹었을 때의 결과는,
다른 사람이 어떤 치료를 받았는지와는 상관없이 정해진다.
- 백신 맞은 사람이 주변 사람한테 면역력을 줘버리는 경우(스필오버) → SUTVA 위반
- 병원마다 약의 질이 다르면 → SUTVA 위반 가능
✅ 인과 추론에서는 "한 사람 = 독립적인 실험 단위"로 간주하기 때문에, 다른 사람의 상태에 영향을 받지 않아야 한다.
📌 2. Positivity – 치료가 무조건 "가능"해야 함
어떤 환자 조건이든, 두 치료를 모두 받은 사람들이 데이터에 있어야 비교가 가능합니다.
- 나이가 80세 이상이면 무조건 약을 안 주는 병원이라면?
→ 그 나이대에 대해서는 치료 그룹과 비교 불가
→ 치료 효과 추정 불가능!
✅ 그래서 인과 추론에서는 “치료도 받고 안 받은 사람 모두 있어야 한다”는 조건이 필요
📌 3. Unconfoundedness – 숨겨진 변수의 영향이 없거나 잘 통제됨
환자가 어떤 치료를 받았는지는 관측된 변수(예: 나이, 병력 등)로 완벽히 설명될 수 있어야 함.
돈 많은 사람만 좋은 치료를 받았고, 소득 정보는 데이터에 없다
→ 소득이 숨은 confounder가 되어 치료 효과 추정이 왜곡됨
✅ 그래서 "모든 혼란 변수(confounder)를 관측해서 모델에 넣었는가?"가 매우 중요하다.
관측 데이터 (EHR)을 사용할 때는 이 가정을 무조건 검토해야 함 (무작위실험에서는 자동으로 만족)

4. Choose the fit the causal ML method
여기에서는 causal ML을 어떤 방식으로 선택하고 적용할 수 있는가에 대한 내용을 다룬다. causal ML method는 추정하고자 하는 estimand와 데이터 유형에 따라 달라지며, 주로 ATE나 CATE를 추정하기 위한 방법들이 발전해왔다.
1. 무엇을 추정할지 결정: ATE, CATE ,....
2. 어떤 방법을 쓸지 선택: 메타러너, causal tree, causal forest, 신경망 등
- 메타러너: 어떤 ML 모델이든 갖다 쓸 수 있음 (결정 트리, 신경망 등)

- model-specific methods (특화된 구조): 기존 ML 모델을 인과 추정에 맞게 수정한 버전
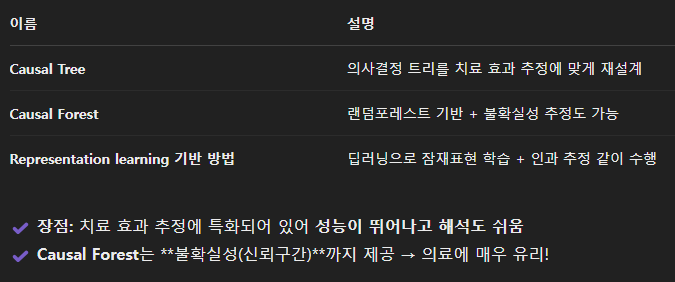
3. 치료가 이산적 or 연속적?: 복용량처럼 연속적인 경우는 특별한 방법(dose-response curve) 필요
4. 불확실성(uncertainty)도 함께 추정하는가?: 의학 분야에서는 표준편차, 신뢰구간 등도 중요
- 의료에서는 단순히 "효과 있음"이 아니라, "그 효과가 얼마나 확실한가"도 중요

다음 포스팅에서 이어서
'Research' 카테고리의 다른 글
| Uncertainty of Treatment Effect (2) | 2025.06.17 |
|---|---|
| Causal Machine Learning에서 Balanced Representation의 의미 (0) | 2025.06.03 |
| [연구 분야 조사] Causal Machine Learning (0) | 2025.04.07 |
| About Circulatory Failure (0) | 2023.09.20 |
| Domain Adaptation in Computer Vision: Everything You Need to Know - Korean Version (2) | 2023.08.06 |


