
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 인과추론 의료
- first pg on this rank that detected no heartbeat of its watchdog.
- 불규칙적 샘플링
- 인과추론
- 리뷰
- 딥러닝
- 분산 학습
- doubleml
- gru-d
- 의료정보
- machine learning
- multi gpu
- GaN
- causal inference
- 토픽모델링
- Time Series
- irregularly sampled time series
- nccl 업데이트
- netflix thumbnail
- Transformer
- causal ml
- 의료
- causal transformer
- causal machine learning
- nccl 업그레이드
- causal reasoning
- causal forest
- pytorch
- ERD
- NTMs
- Today
- Total
데알못정을
[Review]ATM: Adversarial-neural Topic Model 본문
○Introduction
이 논문의 저자는 기존의 통계기반 토픽 모델들이 복잡한 추론 절차(LDA 같은 경우에는 깁스 샘플링)가 필요하고, 단어 수준의 의미를 토픽 모델이 반영하지 않는 문제를 지적하면서 신경망의 적대적 구조를 활용한 새로운 토픽 모델을 제안하였다. 논문에서 제안한 모델의 구성요소를 뜯어 보면서 논문에서 제안한 모델은 토픽 모델링에 어떤 기여를 했는지 정리하고자 한다.
논문에서 제안한 Adversarial-neural Topic Model(ATM)은 총 3가지의 주요 구성요소가 있다.
1) document sample module
2) Generator based on Dirichlet
3) Discriminator
4) Training
순서대로 살펴보면서 이 논문에서 제안한 모델에 대해 뜯어보고자 한다.

○Method
1) document sample module

document sample module은 그림 1에서 제일 상단에 있는 부분으로, 실제 문서 집합을 샘플링 한 후, 그 문서를 표현해주는 벡터를 얻는다. 이때 얻은 벡터는 다음과 같이 weighted TF-IDF 벡터로 구한다.
$$d^i_r=\frac{tf-idf_{i,d}}{\sum_v tf-idf_{v,d}}$$
이때 V는 문서 내 어휘의 개수이다. $i$번째 단어에 대해 TF-IDF 벡터를 구하고 이를 모든 어휘 단위의 TF-IDF로 나누어 Scaling 해준 것으로 이해했다.
2) Generator based on Dirichlet

이 단계의 이름에서 알 수 있듯 Generator $G$는 토픽의 사전 확률 분포를 디리클레 분포로 가정한다. 이러한 디리클레 분포로부터 $\theta$를 샘플링하고, 이 $\theta$를 입력으로 하여 가짜 문서 표현 벡터 $d_f$를 생성한다. 생성기 $G$는 그림 1에서 볼 수 있듯, 3가지의 layer로 구성되어 있으며, 각 layer의 의미는 다음과 같다.
- K 차원의 문서 내 토픽 분포 layer
- S 차원의 임베딩 layer
- V 차원의 문서 내 단어 분포 layer
생성자 $G$의 각 layer에서는 디리클레 분포에서 $\overrightarrow{\theta} $를 랜덤하게 K개 추출하고, 이를 $S$차원의 layer를 통과하여 $V$ 차원으로 매핑한다. 이때 $K$는 잠재 토픽이며 $V$는 문서 내 단어들 즉, 생성한 문서가 되는 것이다. 전체적으로 보면 잠재 토픽 분포로부터 문서가 생성되는 꼴이다. 이때 $\overrightarrow{\theta} $를 S 차원으로 임베딩하는 과정은 다음 수식을 따른다.
$$\overrightarrow{a_s}=max((W_s\overrightarrow{\theta}+\overrightarrow{b_s}),leak*(W_s\overrightarrow{\theta}+\overrightarrow{b_s})) $$
수식에서 활성 함수로 leaky Relu를 사용하는 것을 볼 수 있는데, 이는 활성함수로 Relu를 사용할 경우미분 값이 0이 되어 학습이 되지 않는 문제를 해소하기 위해 사용했다고 한다. 또 마지막 layer로 mapping 될 때는 각 노드 값과 weight를 아핀 변환 함수의 결과를 출력하며 활성 함수로 Softmax를 사용하여 출력한다. 이때 출력된 결과는 생성된 가짜 문서 $d_f$의 $i$번째 단어의 등장확률을 의미한다.
3) Discriminator
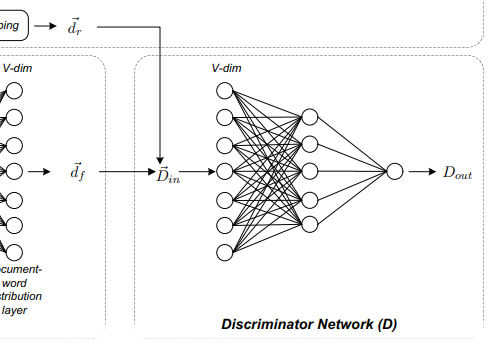
판별기는 생성기로부터 생성된 가짜 문서 $d_f$와 실제 문서의 TF-IDF 벡터인 $d_r$를 입력으로 하고, 스칼라 값인 $D_out$을 출력한다. 이때 $D_out$이 큰 값이라면 판별기가 입력 데이터를 실제 데이터라고 확신하는 정도가 크다는 것을 의미한다.
4) Training
기존 GAN은 Generator가 생성한 이미지의 분포와 실제 이미지의 분포 사이의 거리를 최소화하는 방향으로 최적화하는 것을 목적으로 한다. 이 논문에서도 GAN과 비슷한 목적함수를 가질 것이라 예상했지만 실제 목적함수는 그러지 않았다. GAN에서 사용하는 KL-Divergence 는 “Mode Collapse”라는 문제가 존재한다. “Mode Collapse”란 생성자가 다양한 이미지를 만들어 내지 못하고 비슷한 이미지만 생성하는 문제이다. 이는 Discriminator가 잘 속는 label인 데이터를 잘 파악한 결과로 Generator가 같은 이미지만 생성하여 Loss를 줄이려고 하기 때문에 발생한다. 따라서 논문의 저자는 이러한 점을 지적하면서 Earth-Mover’s Distance를 사용했다. Earth-Mover’s Distance는 서로 같게 만들고 싶은 분포 $p$와 $q$가 있을 때 분포 $p$에 있는 확률 더미를 옮겨 분포 $q$와 똑같이 만들기 위해 필요한 일의 양으로 생각할 수 있다.

예를 들어 그림 2를 보면, 파란 박스 하나의 무게가 1/9일때, 위에 있는 분포를 아래에 있는 분포와 똑같이 만들기 위해서는 5에서 11, 5에서 10, 5에서 9, 4에서 8, 4에서 6, 3에서 5, 3에서 4로 총 27칸 이동해야한다. 이는 평균적으로 27/8=3.375칸 이동한 것이다. 각 이동에 1/9의 무게를 옮겨야 하므로 일의 양은 1/9*3.375 = 0.375이다.
따라서 Earth-Mover’s Distance를 이용하여 기존의 KL-Divergence term을 아래 식이 대체한다.
$$L_d = \underset{d_f\sim p_g}{\mathbb{E}}[D(d_f)]-\underset{d_f\sim p_r}{\mathbb{E}}[D(d_r)]$$
또한 이러한 Earth-Mover’s Distance와 더불어 학습의 안정성을 도모하기 위한 장치로써 gradient penalty를 도입했다. 처음에 논문을 읽을 때, gradient penalty가 어떤 의미며, 왜 존재하는지에 대해 논문에서 설명하지 않아서 이해하는데 다소 어려웠다.
본 논문에서 인용된 논문[2]을 통해 gradient penalty에 대해 이해할 수 있었고, 그 내용을 여기서 정리하면서 gradient penalty의 의미를 파악하고자한다.
우선 Lipschitz 함수의 성질에 대해 간단히 언급하자면, $x_1,x_2\in R$에 대해서 $|f(x_1)-f(x_2)|\leq K|x_1-x_2|$를 만족하는 실수값 $K\geq 0$이 존재할 때, $f(.)$는 K-Lipschit-z continuous를 만족한다. 이 식을 조금 변형해서 다시 쓰면 다음과 같다.
$$\frac{|f(x_1)-f(x_2)|}{|x_1-x_2|}\leq K$$
즉, $f(.)$는 기울기가 K 이하인 함수로 아주 직관적으로 이해할 수 있다. K-Lipschitz continuous를 만족하는 함수는 그림 3처럼 함수를 어떠한 점에서 미분하더라도 기울기가 분홍색 경계를 벗어날 수 없다.

본 논문에서 제안한 gradient penalty의 수식은 다음과 같다.
$$\widehat{d}=\epsilon d_r+(1-\epsilon)d_f, \epsilon\sim \mathbb{U}[0,1]$$
$$L_{gp} = \underset{d_f\sim p_{\widetilde{d}}}{\mathbb{E}}[(\left\|\triangledown _{\widetilde{d}}D(\widehat{d}) \right\|_2-1)^2]$$
$L_{gp}$를 통해 본 논문에서는 1-Lipschitz continuous 제약을 준 것을 알 수 있다. 수식을 보면 Discriminator의 기울기 값이 1을 넘어가게 되면 $L_{gp}$값이 커지게 된다. 즉, 이 수식은 가짜 문서 $d_f$와 실제 문서 $d_r$사이의 값을 넣은 Discriminator를 아무리 미분을 하더라도 기울기가 1을 넘지 못하도록 제한하는 의미를 담고 있다. 이는 gradient exploding을 효과적으로 막을 수 있으며, GAN의 구조를 가진 제안된 모델의 학습 안정성을 높일 수 있다. 따라서 본 논문에서는 이 두 가지 Loss function을 선형결합하여 다음과 같은 Objective function을 제안했다.(이때 $\lambda$는 얼마만큼의 제약을 줄 것인지 결정하는 하이퍼파라미터이다.)
$L = L_d + \lambda L_{gp}$
충분히 학습된 Generator는 토픽 분포를 단어분포로 매핑하는 함수가 된다. 따라서 토픽의 수 K를 지정해 놓고 첫 번째 토픽에 대한 문서 내 단어 분포를 얻고 싶을 때는 토픽의 인덱스를 의미하는 one-hot vector $ts_1=\left [ 1,0,...0 \right ]^T$를 $G$에 입력하여 얻을 수 있다.
○Experiment
| Dataset | 설명 |
| Grolier | Grolier Multimidia Encyclopedia로부터 만들어졌으며, 스포츠, 경제, 정치 등 세계의 거의 모든 분야를 망라하는 29,762개의 문서가 있음 |
| NYtimes | 1987년 1월 1일부터 2007년 6월 19일까지 뉴욕 타임즈가 작성하고 발행한 뉴스 와이어 기사 모음이다. 정치와 오락 같은 현실 세계의 광범위한 topic을 갖고 있다. |
저자는 Topic coherence에 대해 제안한 모델을 평가했다. TC 점수를 측정하기 위한 측정 지표로는 C_P, C_A, NPMI, UCI, UMass로, 총 5가지 지표에 대해 모두 평가했다. 각 평가 지표는 나름대로의 일관성을 측정하는 수학적 공식으로 정의되어 있다. 이 다섯가지 지표 역시 여기에서 소개한 것과 같이 palmetto 사이트에서 제공하는 서비스를 이용했다고 밝히고 있다.

그림 4는 실험 결과 테이블이다. 그림 4에서 알 수 있듯이, 제안한 모델인 ATM의 TC 점수가 다른 모델에 비해 높은 향상을 이루어냈다. 저자는 그 이유를 다음과 같이 설명했다.
- 토픽 생성 사전확률분포로 가우시안 분포를 가정한 NVDM 및 logistic normal distribution(로짓이 정규 분포를 갖는 확률 변수의 분포)을 사전확률분포로 가정한 LDA-VAE, ProdLDA를 제안한 모델 ATM과 비교했을 때 디리클레 분포를 가정한 것이 말뭉치에서 더 다양한 topic의 양상을 포착하고 더 일관성 있는 주제를 얻을 수 있게 함
- 신경망의 강력한 표현 능력이 성능 향상에 기여했음
개인적으로 같은 디리클레 분포를 가정했지만 LDA보다 높은 성능을 이룰 수 있었던 이유는 신경망의 표현능력이라는 것에 동감하는 입장이다. 디리클레 분포는 하이퍼파라미터 $\alpha$에 따라 확률 변수의 확률 분포가 다양하게 변화한다.

적절한 $\alpha$는 토픽이 생성될 확률을 다양하게 부여할 수 있고 이를 기반으로 신경망 기반의 생성모델을 적용하였기 때문에 LDA보다 높은 topic coherence를 얻을 수 있었다고 생각한다.
○정리 및 활용할 점
개인적으로 느꼈던 본 논문의 contribution은 Earth-Mover distance와 gradient penalty를 사용하여 GAN의 학습 불안정성을 고려하면서,GAN의 학습 불안정성을 고려하면서 이를 토픽 모델링에 적용한 것이다. 하지만 본 논문에서 볼 수 있었듯이 단순히 디리클레 분포에서 샘플링 되어진 잠재 토픽 분포로부터 생성한 가짜 문서의 분포를 실제 문서의 TF-IDF 벡터와 가깝게 만드는 것은 단어 사이의 연속성을 통해 알 수 있는 문맥적 의미를 고려하지 못한다고 생각하며, 이 부분이 이 논문에서 제안한 모델의 단점이라고 생각한다. 실험에서도 단어의 순서를 고려하여 문맥적 의미를 반영한 신경망 기반의 모델과 어떠한 비교도 없었다. 만약 단어의 문맥적 의미를 반영한 모델들과 TC 점수를 비교한다면 본 논문에서 제안한 모델의 TC 점수는 낮을 것 같다는 생각이 들었다. 왜냐면 3.1.2에서 다루었던 논문에서 알 수 있듯이(LSTM 구조에 attention machanism을 적용하여 단어의 문맥적 의미 및 순서를 고려했던 모델), 단어 문맥적 의미를 고려했을 때 TC 점수가 높았기 때문이다.
참고문헌[1]https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=swkim4610&logNo=220970999014[2]Ishaan Gulrajani, Faruk Ahmed, Martin Arjovsky, Vincent Dumoulin, and Aaron C Courville. Improved training of wasserstein gans. In Advances in Neural Information Processing Systems 30, pages 5767–5777. Curran Associates, Inc., 2017.



