
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- pytorch
- 의료
- nccl 업데이트
- causal reasoning
- 의료 의사결정
- gru-d
- doubleml
- causal ml
- 불규칙적 샘플링
- causal inference
- netflix thumbnail
- NTMs
- Transformer
- GaN
- 토픽모델링
- machine learning
- ERD
- irregularly sampled time series
- 딥러닝
- multi gpu
- 인과추론 의료
- 의료정보
- causal machine learning
- 패혈증 관련 급성 호흡곤란 증후군
- nccl 업그레이드
- first pg on this rank that detected no heartbeat of its watchdog.
- 분산 학습
- nccl 설치
- 리뷰
- Time Series
- Today
- Total
데알못정을
[Review] Learning document representation via topic-enhanced LSTM model 본문
[Review] Learning document representation via topic-enhanced LSTM model
쩡을이 2022. 12. 20. 18:35이 논문은 document representation 즉, 문서 표현에 대한 논문이다. 문서들을 대표하는 표현을 추출하는 알고리즘을 LSTM의 모듈을 응용하여 새로운 알고리즘을 제안했다. 이번 포스트에서는 본 논문의 기술 순서에 따라 핵심 내용을 정리하고자 한다.
○Abstract
문서 표현은 텍스트 마이닝, 자연어 처리 및 정보 검색 분야에서 중요한 역할을 한다. 문서 표현의 전통적 접근법은 각 단어가 독립적으로 존재함을 가정하고, 동의어에 대한 충분하지 않은 고려로 인해 문서 간 상관관계나 단어의 순서 정보가 무시되는 문제를 겪을 수 있다. LSTM과 같은 순서를 고려하는 모델은 이 문제를 해결하는데 효과적이지만, 단순히 LSTM만을 사용하면 문서 표현을 학습하기 위해 문서 전체 의미를 파악하는데에는 적절하지 않을 수 있음을 지적하면서 강화된 LSTM 모델을 제안한다고 강조하고 있다.
○핵심 방법론
논문에서 제안한 모델은 Sequence modeling layer, attention modeling layer, Topic layer, Representation layer로 이루어져있다.
1. Sequence modeling layer
Sequence modeling layer에서는 기존 LSTM 구조처럼 순서가 있는 데이터가 입력이 된다. 이때 입력되는 데이터는 word2vec으로 임베딩 한 단어 시퀀스의 벡터가 되며, LSTM의 셀 구조를 그대로 적용하여 각 hidden state와 memory cell 정보가 계산된다.
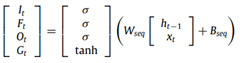

이때 hidden state의 의미는 단어 사이의 문맥 정보에 대한 요약이라고 설명하고 있다. 그 이유는 현재 관찰된 단어 외에도 과거 시점의 hidden state가 순차적 구조를 통해 현재 hidden state에 활용되었기 때문이다. 동일한 단어라 하더라도, 시퀀스 사이에서 문맥이 바뀌면 다른 표현을 가질 수 있다. 이러한 부분을 LSTM의 구조를 이용하면 고려할 수 있다고 설명하고 있다.이렇게 계산된 hidden states($H_s=\left\{h1,...,h_n \right\}$)와 업데이트된 memory cells(C_s=\left\{C1,...,C_n \right\})은 다음 계층인 Attention layer의 입력으로 사용된다.
2.Attention modeling layer
Attention layer는 Sequence modeling layer과 Latent Topic layer를 연결한다. 이전 layer의 hidden state 즉 각 단어의 문맥 정보 중 어떤 부분이 다음 layer 인 topic layer에서 topic 탐지하는데 가장 중요한지 평가할 수 있다. 이를 쉽게 풀어 해석하면, 단어를 독립적으로 보고 토픽을 추정하지 않고 문맥 정보를 보고 추정하는데, 여러 문맥 정보(hidden state)에 어디에 집중할지 볼 수 있도록 Attention machanism을 적용했다고 볼 수 있다. 일반적으로, latent topic는 의미론적으로 관련된 단어들의 시퀀스에서 표현되므로, 관찰된 각 단어는 다양한 주제들과 서로 다른 연관 관계를 보일 수 있다. 예를 들어, "전쟁이 진행됨에 따라, 자동차 산업에서 우려를 불러일으켰던 유가가 사상 최고치를 기록했다."라는 문장에서 "전쟁"이라는 단어는 "경제"와 "기술"과 같은 다른 주제에 비해 "군사"라는 주제와 훨씬 더 관련이 있다. Attention modeling layer은 latent topic과 관련하여 개별 단어의 hidden state의 Attention weight를 자동으로 추정할 수 있다. Sequence modeling layer와 Attention modeling layer가 동작하는 과정은 다음 그림 1의 해당 부분을 보면 알 수 있다.

Attention layer에서는 각 단어의 문맥 정보인 hidden states를 활용하여 다음 일련의 계산으로 Attention weight를 계산한다.
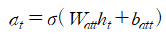
attention 수식 1의 결과인 $\alpha_t$ 는 hidden states와 latent topic 사이의 연관도로 해석하고 있다. 시그모이드 함수를 씌움으로써 값이 0과 1사이에 존재함을 알 수 있다.

모든 시점의 hidden state에 대해 attention weight를 계산하면 attention 수식 2와 같다. 주목할 점은 계산된 $\widetilde{A}$는 각 원소들이 0에서 1사이 값이지 $\widetilde{A}$matrix의 전체 합이 1이 아니다. 따라서 attention 수식 3과 같이$\widetilde{A}$행렬에 Softmax 함수를 취하여 Scaling을 해준다.

이렇게 얻은 수식 3의 결과 $A$는 모든 hidden state에 대한 Scaled Attention weight이다.
3. Latent Topic modeling layer
여기서는 Attention layer에서 만들어진 Attention weight를 가지고 $H_s$와 $C_s$를 이용하여 잠재 토픽(들) $T_s$와 $TC_s$를 만들어낸다.

4. Topic similarity constraint
기존의 많은 연구들은 Topic의 중복가능성을 간과하였다. 실제 예상되는 문서의 토픽은 “군사”, “경제”, “건강” 일 때, similarity constraint(유사성 제약)을 사용하지 않을 경우 “국방”, “무기”, “경제”, “건강” 이 될 수도 있다고 이야기 하면서, 이 제약조건이 필요하다고 이야기 하고 있다. 직관적으로 이해하기론 국방, 무기에 해당하는 토픽 내의 단어들이 서로 비슷하여 이를 두가지 토픽으로 나눌 수 있을지에 대한 문제를 해결하기 위해 유사성 제약을 주는 것 같다.즉 토픽별로 서로 유사하지 않도록 일종의 regularization을 수행한다고 이해했다.(실제로 이는 Loss term을 보고 regularization term으로써 유추할 수 있었다.) 유사성 제약 매커니즘은 각 문서는 잠재 토픽 정보로부터 특정지어지며, 각 토픽의 정보는 hyperspace에서 창조된다는 가정이 있다. 즉 토픽이 창조되어야 문서가 생성된다는 가정을 세운 것인데, 토픽이 창조될 때 토픽간의 유사도가 낮게끔 제약을 준다는 아이디어다. 이를 그림으로 나타내면 그림 2와 같다.
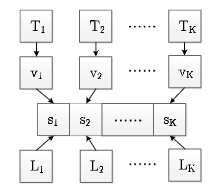
본 논문에서, topic의 label은 원-핫 벡터($L_k$)로 표현되며, 공간(hyperspace)의 기초로 취급될 수 있다. 여기서는 서로 구별되고 다양한 잠재적 의미론적 주제를 학습하는 것이 목적이다. 유사성 제약은 토픽 프로젝션 벡터 $v_k$와 토픽 label 정보 $L_k$사이의 유사성을 측정하는 것이다. 이때 $v_k$는 토픽 정보 $T$로부터 계산되고, $L_k$는 수동적으로 생성하는 원-핫 벡터이다.($L_1$이라는 것은 항등행렬의 한 행이라고 설명을 덭붙이고있다.)
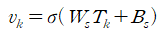
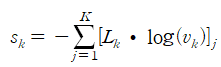
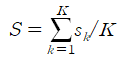
수식 3의 결과인 S를 줄이면 토픽 벡터 $T$간의 차이가 더 커지게 된다고 한다. 근데 한 가지 궁금한 것은 수식의 의미이다. 논문의 저자는 이 결과가 왜 유사도를 의미하는지 설명을 충분히 하지 않아서 이해하는데 정말 어려웠다.
나름대로의 해석을 붙이자면, 일단 논문에서 각 토픽 정보들($Ts$)과 토픽 label($Ls$) 사이의 유사도를 구한다고 했다. 여기서 토픽 정보($Ts$)는 문서 내 단어의 문맥적 의미를 함축한 hidden state와 attention weight를 활용하여 구한 선형 변환 값이다. 또 토픽 label은 아까 언급했듯이 각 토픽의 위치 및 기저가 되는 one hot vector이다.
만약 토픽의 갯수를 사전에 3개로 지정했다고 가정하고 유사도를 구해보았다.
먼저 토픽의 갯수가 3개일 때 각 $Ts$는 다음과 같다.
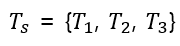
또 이를 기반으로 Simliarity constraint 수식 1 을 통해 계산된 프로젝션 벡터는 다음과 같다.
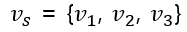
또 $L_1$은 다음과 같다.
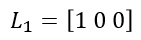
이제 $s_1$을 구해보자. Simliarity constraint 수식 3에 따라 다음과 같이 계산된다.
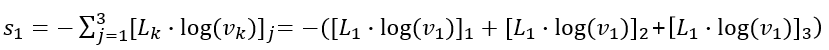
결국 label 벡터의 희소성으로 인해 첫 번째 원소만 값을 가지며 $s_1$은 다음이 된다.
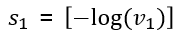
같은 방식으로 $s_2$, $s_3$은 다음과 같고
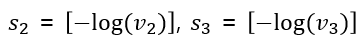
결론적으로 유사도 $S$는 다음과 같다.
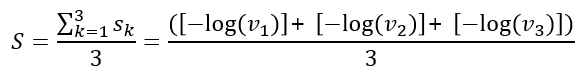
이 의미는 무엇일지 고민을 많이했다. 결론적으로 위의 유사도 식을 로그의 성질을 이용하여 변환하면 다음과 같다.
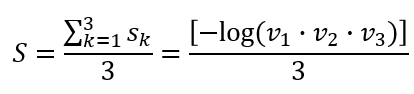
즉 토픽의 정보를 프로젝션한 벡터 $v_1$, $v_2$, $v_3$를 곱한 꼴이 된다. 이는 유사도의 의미를 담을 수 있고 결국에 $S$가 커진다면 세 토픽간의 유사도가 크다는 것을 의미한다. 논문에서 그저 $v_k$, $s_k$, $S$ 가 어떻게 계산되는지만 표시하고 넘어가서 이런 디테일 한 부분을 판단하기 어려웠다. 결론적으로 이 유사도를 의미하는 $S$는 목적함수에서 regularization term으로 구현된다.
5. Tree-LSTM representation layer
이제 마지막 단계인 문서 표현 벡터를 생성하는 layer이다.(제일 상위 계층) 앞에서는 토픽의 정보를 학습했으므로 이를 이용하여 이 문서의 전체 표현 벡터를 생성한다고 이해했다. 다음 수식 그림과 같이 LSTM의 셀을 계산하는 방식으로 K개의 토픽 셀을 하나의 출력으로 바꿔주었다. 한 가지 궁금한 것은 forget gate의 계산이다. 논문에서는 각각의 자식 노드인 토픽 노드들이 고유한 forget gate가 존재하게 된다고 한다. 그림 35에서 두 번째 수식에 해당하는 내용이다. 근데 이 forget gate가 존재하는 건 둘째 치고 수식의 의미를 잘 모르겠다. 논문에서 자세히 기술하지 않아 차후 보완할 점으로 설정하였다.
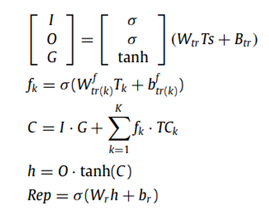
결과론적으로 representation layer의 결과는 0부터 1사이의 값으로(시그모이드의 영향) 나오는데, 이는 문서 1개를 0과 1사이의 벡터로 변환하는 꼴이다. 아무튼 이렇게 문서를 하나의 벡터로 표현하고나서, softmax classifier를 마지막에 적용하여 이 문서의 label을 예측한다. 아래의 수식은 classifier의 objective function이다. 이를 이용하여 그림 1에서 봤던 제안 알고리즘을 최적화한다. 전체적인 형태는 cross entropy에 regularization term이다.
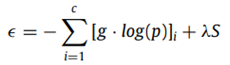

○EXPERIMENT
논문에서 저자는 다음 4가지 부문에서 제안한 모델의 성능을 증명하고자 했다. 본 포스트에서는 그 중 3가지에 대한 리뷰를 하려고 한다.
- Document Classification
- Topic Detection
- Information Retrieval
- Document Clustering
사용한 데이터셋과 기본 정보는 다음과 같다.
| Dataset | 설명 |
| 20Newsgroup | 20,000개의 문서를 20개의 서로 다른 뉴스 그룹(서로 다른 주제)에 대해 균등하게 모은 데이터셋 |
| Wiki10+ | 2009년 4월 소셜 북마크 사이트 딜리셔스와 위키백과에서 검색한 데이터로 만들어진 데이터 집합. 20,764개의 영어 위키 백과 문서와 해당 태그의 고유 URL이 포함되어 있음 |
| Amazon reviews | 4개의 다른 도메인으로 구성되어 있고, 각 문서는 2개의 감성 클래스 중 1개(이진 분류) |
| SemEval2007 | 1250개의 문서로 이루어져 있고, 화, 혐오, 공포, 즐거움 등 총 6개의 감정으로 labeling되어진 데이터 셋 |
1) Document Classification result
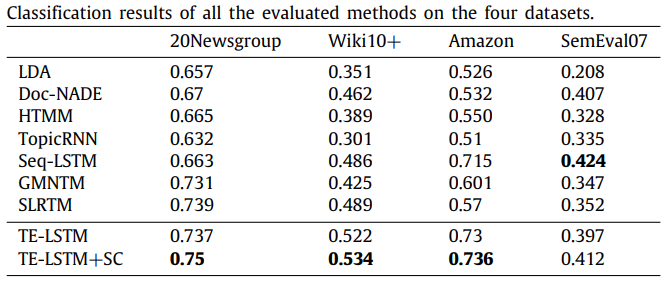
실험 결과 제안 모델이 더 나은 벡터 표현을 할 수 있음이 밝혀졌다. Wiki10+ 은 클래스 불균형 데이터이기 때문에 micro-f1 score를 사용했고, 나머지 데이터셋에 대해서는 accuracy를 측정했다고 한다.
실험의 결과를 요약하면 다음과 같다.
- Topic similarity constraint가 있는 모델, 없는 모델 둘다 분류 문제에 대해 다른 모델보다 향상된 성능을 달성함
- Wiki10+ 는 클래스 불균형 데이터이지만 다른 모델보다 더 좋은 성능을 낼 수 있었음
- SemEval2007 데이터는 short text라 충분한 잠재 topic 정보를 학습하지 못해 성능 향상을 이루지는 못함
- Attention machanism을 사용하지 않은 seq-LSTM보다 대부분의 데이터셋에서 성능이 좋은 것으로 봐서 제안된 모델의 attention machanism이 토픽 표현에 도움이 되었음을 알 수 있음
또한 저자는 Topic similarity constraint의 효과를 검증하기 위해 Test data를 topic similarity score에 따라 내림차순으로 정렬하고 동일한 크기의 15개 배치로 나누어 평균 분류 정확도를 plot 했다.(배치의 순서가 뒤쪽일 수록 토픽간 유사도가 낮다.)
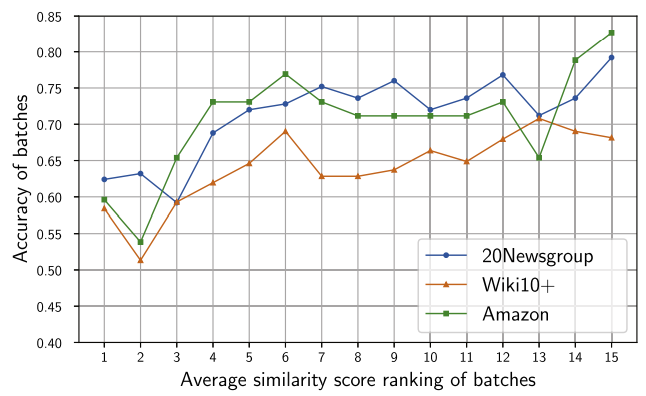
그림과 같이 모두 평균정확도가 상승하고 있다. 즉, 발견된 토픽이 비슷하지 않을 수록 모델의 성능이 향상된다는 것을 증명했다.
2) Topic Detection result
토픽들은 의미적으로 비슷한 단어들의 군집을 통해 파악할 수 있다.(사용자가 임의로) 저자는 비교모델로 word2vec과 LDA가 결합된 모델인 LDA2vec에서 실혐했던 것과 같은 방식으로 제안 모델에 대해서 실험하여 두 모델을 비교했다.
Topic이 얼마나 잘 추출되었는지 평가하기 위해서 제안모델의 attention 강도가 높은 상위 5개의 단어를 토픽을 설명하는 하나의 군집으로 보고 TC 점수를 측정하였다.(TC 점수의 개념과 단점에 대해)
TC점수의 단점은 계산 방식이 다양하여 논문간 비교가 어렵다는 것이다. 본 논문에서 저자는 TC점수를 계산해주는 서비스를 이용한 것 같다. (https://palmetto.demos.dice-research.org/) 링크에 가서 토픽을 설명할 수 있는 단어(최대 10개 입력가능)를 입력하면 TC점수를 알아서 계산해준다.
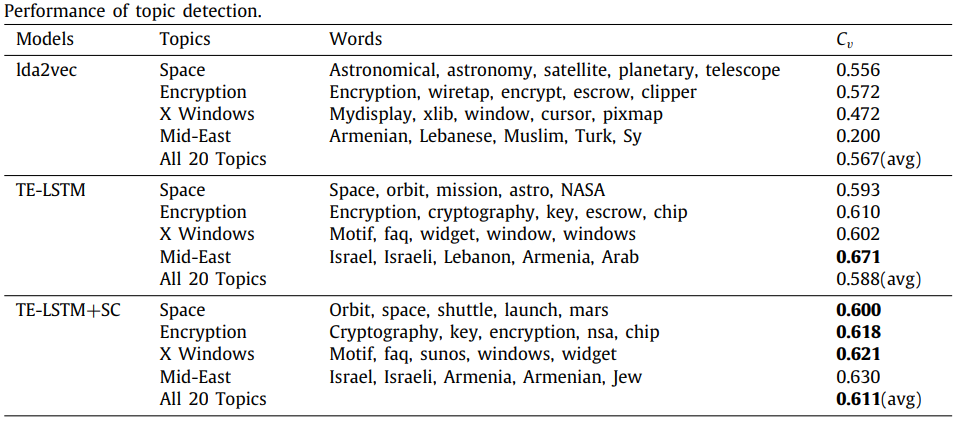
실험 결과 제안 모델이 모두 TC점수가 높았다. 즉, 제안된 모델에 의해 발견된 단어 군집들이 토픽과 적절하게 관련되어 있음을 알 수 있다. 게다가 제약 조건을 준 버전의 제안모델(맨 마지막 행)이 그렇지 않을 때 보다 TC점수가 높았다. 이는 Topic similarity constraint가 topic coherence를 높이는데 도움이 됨을 알 수 있다.
4) Document Clustering
제안 모델의 출력값은 문서의 의미를 함축한 실수 벡터이다. 논문에서 K-means 알고리즘을 사용하여 문서 군집화 작업을했다고 한다. 이는 문서가 서로 비슷하면 표현 벡터들 또한 서로 거리가 가까울 것이라는 가정을 세운 것이다.(20NewsGroup은 20개의 군집, Wiki10+은 25개의 군집을 초기에 설정하고 실험을 진행했다.)
또한 각 문서에 있는 카테고리 정보가 군집에 얼마만큼의 비율(%)로 할당되었는지 측정하여 정량적 평가를 할 수 있도록 하였다.
table 10과 11은 20NewsGroup 데이터 셋에 대한 군집화 결과이다.
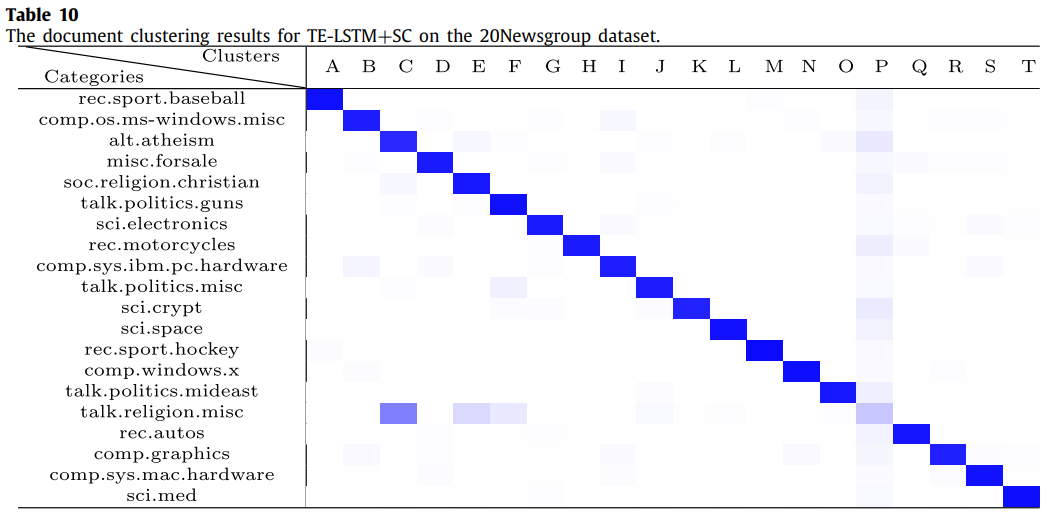
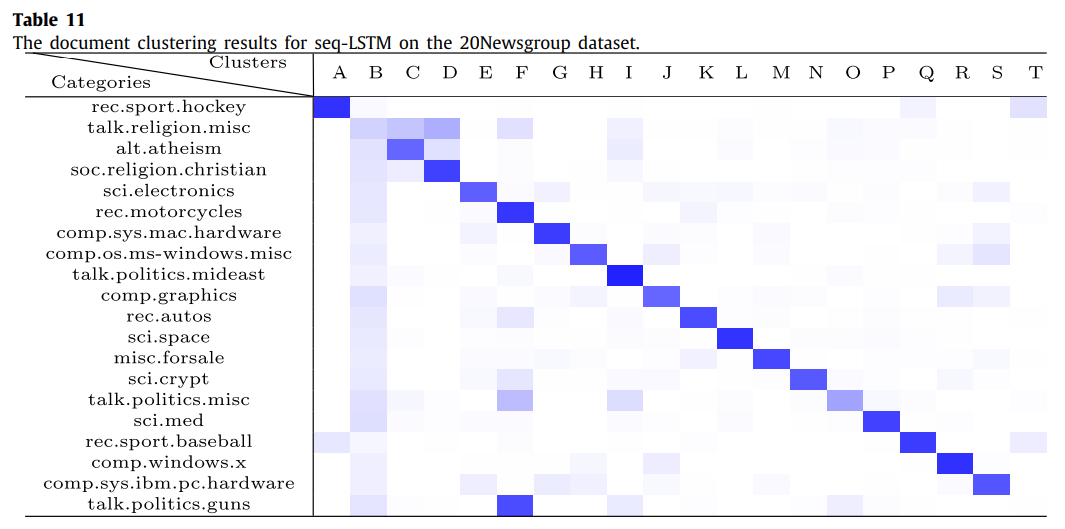
제안한 모델의 군집화 결과가 더 뚜렷하다. 각 클러스터에 카테고리들이 비교 모델인 seq-LSTM 보다 안겹치게 할당되었기 때문이다. table 10에서 클러스터 C는 약간 겹치는 것을 볼 수 있는데, 이 실험은 개인적으로 매우 의미가 있다고 생각한다. 그 이유는 상관관계가 있는 두 단어 "religion"과 "atheism" (종교와 무신론)를 벡터로 적절히 표현하여 표현된 벡터 역시 서로 밀접한 관계를 유지하고 있으므로 제안한 모델이 문서 표현을 잘 한다는 것이 증명되었기 때문이다.
○마무리하며
우선 본 논문에서 제안된 모델의 주요 task는 “Document2Vec”으로 표현할 수 있다. 문서를 0과 1사이의 실수 벡터로 표현하는 것이 주 목적이고, 이를 통해 문서 분류, 토픽 탐지, 군집화 같은 텍스트 마이닝에 적용할 수 있다. 이 논문의 가장 큰 Contribution으로 생각되는 점은 토픽이 생성될 때 어떤 단어에 초점을 맞추어 토픽을 생성할 것인지 결정할 수 있는 attention machanism을 적용한 것이다. 또 이때 생성된 토픽들이 서로 유사성이 낮게끔 조절해주는 제약조건을 통해 TC 점수에서 큰 향상을 이루어냈다. 앞으로 토픽모델링 관련 과업을 수행할 때 이 논문에서 배우고 활용할 점은 실험에 있다. 가장 인상 깊은 실험은 Topic Detection이다. Survey 논문에서 언급되었다시피, TC 점수는 논문마다 계산 방법이 달라 비교할 수 없다는 것이 단점이었다. 하지만 이 논문의 실험처럼 Palmetto를 사용하여 모델 간 TC 점수 비교를 한다면 앞으로 프로젝트나 연구를 할 때 TC 점수를 통해 모델 간 비교 및 개발할 알고리즘의 성능을 측정할 수 있을 것 같다.



