
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- m/m/s
- moirai
- 리뷰
- queueing theory
- first pg on this rank that detected no heartbeat of its watchdog.
- 불규칙적 샘플링
- ERD
- irregularly sampled time series
- nccl 업그레이드
- Time Series
- timesfm
- timellm
- GaN
- multi gpu
- nccl 업데이트
- 분산 학습
- pre-trained llm
- 의료정보
- operation management
- nccl 설치
- gru-d
- NTMs
- ed boarding
- 패혈증 관련 급성 호흡곤란 증후군
- length of stay
- 대기행렬
- Transformer
- 딥러닝
- 토픽모델링
- pytorch
- Today
- Total
데알못정을
[Review]GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models 본문
[Review]GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
쩡을이 2022. 9. 30. 18:37오늘 포스팅에서 리뷰할 논문은
"GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models"이며, 이 논문은 2021년 12월 open ai에서 나온 논문이고, text를 image로 생성한다는 점에서 DALL-E와 목적은 같지만, Diffusion model을 사용하여 구현했다는 특징이 있다. 이 논문은 CLIP guidance 학습 방법과 Classifier-free guidance 학습 방법을 비교하여 실험 결과를 제시하고 있다.
Introduction
최근 guidance technique이 diffusion model의 이미지 생성 결과를 high quality로 만들어 주었다. [4]“Diffusion models beat GANs on image synthesis." 에서는 diffusion model이 classifier의 true label에서 조건화 할 수 있도록 하는 기술인 “Classifier guidance”로 noise에서 이미지가 생성될 때 샘플을 label쪽으로 유도하여 사실적인 이미지를 생성하였다. 또한 [2] Ho & Salimans(2021) "Classifier-free diffusion guidance.“ 에서는 label이 있는 diffusion model과 없는 diffusion model의 예측 사이를 보간하는 형태인 Classifier free guidance를 사용하여 별도로 훈련된 분류기 없이 위 연구와 유사한 결과를 달성했다.
저자는 노이즈 샘플에서 이미지를 생성하는 diffusion model에 이러한 guiding 기술이 더욱 photorealistic한 이미지를 생성할 수 있다는 것을 발견하였고, Text conditional image synthesis 문제에 두 가지(CLIP guidance, Classifier free guidance) guiding 기술을 diffusion model을 적용하여 이 둘을 비교하였다. 저자는 이러한 Diffusion model을 “Guided Language to Image Diffusion for Generation and Editing”로, 줄여서 “GLIDE”라 언급하고 있다.
GLIDE가 할 수 있는 것은 다음과 같다. GLIDE는 text를 반영하여 다양한 이미지를 생성할 수 있다.

저렇게 'a corgi wearing a red bowtie and purple party hat" 이라는 문장을 입력하면 코기가 빨간 리본과 보라색 파티모자를 쓰고 있는 사진이 생성된다. GLIDE는 특정 영역에 text condition을 주어 원하는대로 합성이 가능한데, 이러한 기술을 "inpainting"이라고 논문에서 언급하고 있다.

저렇게 초록색으로 칠해진 영역처럼 공간을 지정하고 거기에 text condition을 주면 text에 충실하게 이미지가 바뀐다. 또한 sketch와 text caption guide를 줘서 image를 edit할 수도 있다. 이를 논문에서는 "SDEdit" 라고 표현하고 있다.

왼쪽 사진이 원본인데 여기에 sketch를 추가하고(가운데 사진) text로 "only one cloud in the sky today" 라는 조건을 주면 맨 오른쪽 사진 처럼 구름이 추가된 사진이 생성된다.
이러한 것들이 어떻게 가능할까?
Background
이 논문을 온전히 느끼기 위해서는 몇가지 background가 필요한데 이제부터 몇가지 개념들을 남겨보겠다.
1.DDPM(Denoising diffusion probabilistic models)
[5], [6]DDPM은 diffusion model에 관한 내용이다.
diffusion model은노이즈 x_T 를 샘플링해서 x_(T-1),x_(T-2),…,와 같이 점점 노이즈가 줄어드는 샘플을 생성한 후 최종적으로 노이즈가 없는 x_0를 생성하도록 노이즈를 예측하는 모델이다. Diffusion model은 x_t 로부터 “denoised”한 x_(t-1)을 생성하도록 학습이 진행된다.
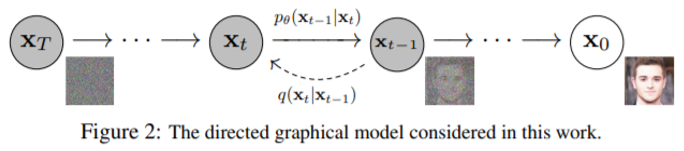
이러한 diffusion model은 크게 두 단계로 이루어져있다.
(1) Forward process
초기 이미지 상태 x_0에서 각 time step을 따라 마지막 시점 T까지 노이즈를 입힌다. 이때 T 시점의 데이터는 완전한 노이즈로 gaussian distribution을 따른다.
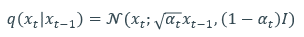
수식에서 q는 x_(t-1) 이미지에서 노이즈가 입혀진 x_t 이미지의 probability를 의미한다. 오른쪽 term을 보면 x_(t-1)에 root alpha_t 만큼 곱하는데 이는 root alpha_t 만큼 x_(t-1)의 정보를 의미하고 (1-alpha_t)에 1을 곱한 것은 (1-alpha_t)I 만큼의 노이즈를 더하겠다는 의미이다. 이렇게 생성된 x_t는 정규분포를 따른다. t=0 부터 t-1까지 반복하면 우리는 완전한 noise distribution을 얻는다.
(2) Reverse process
Reverse process는 forward process의 최종 결과인(완전한 노이즈 상태) x_t 에서 다시 원본 상태인 x_0 로 복원하는 과정이다.
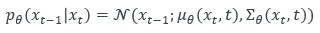
수식에서 p의 의미는 x_t를 가지고 있다는 조건하에 x_(t-1)의 발생 확률을 의미한다.(근데 파라미터 theta가 있는)우리가 추정해야할 것은 각 시점 사이의 추가되어지는 noise의mean 값과 variance이다. DDPM에서는 이러한 gaussian distribution의 mean 값을 찾는 문제를 noise를 예측하는 문제로 수식을 조금 유도하여 바꿔버렸는데, 이에 대한 자세한 과정은 reference에 경로를 남겨두겠다.(꼭 보는거 추천) 자세한 설명을 달지 않는 이유는 지금 GLIDE 논문에 대한 리뷰를 하고 싶은데 deep하게 설명을 해버리면 재미가 없을 것 같다. 따라서 predict noise와 true noise 간의 MSE loss를 training object로 설정하여 diffusion model의 forward process를 수행할 수 있다. 논문에 나와있는 Algorithm 1과 다음의 수식을 참고하면 쉽게 이해할 수 있다.

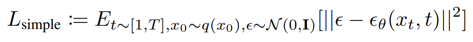
Algorithm 1과 아래의 L_(simple)은 같은 의미인데, 아무것도 안붙어 있는 epsilon이 noise gaussian distribution을 의미하고, epsilon_theta가 우리가 추정한 시점 사이에 추가된 noise이다. 이 둘의 차이를 최소로 만들어주도록 loss를 정의하면 우리는 각 시점사이에 추가되는 좋은 gaussian noise를 추정할 수 있다. 각 시점에 추가되는 노이즈를 알기 때문에 각 시점에 노이즈가 제거된 다음 step의 데이터도 만들어 낼 수 있다. 이는 Algorithm 2를 t번 반복 하면된다.

이에 대해 그림으로 잘 설명한 예시가 있어서 그 표현 방식을 본따서 Algorithm 2를 아래와 같이 표현해보았다.
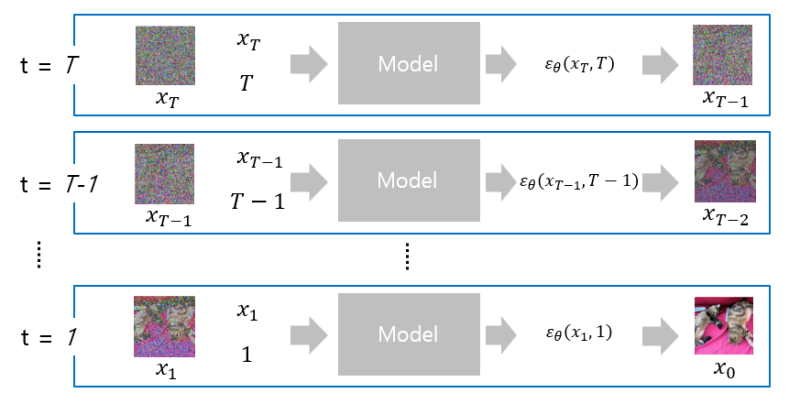
forward process에서 얻은 결과인 x_t와 시점 정보 t를 MODEL에 넣고 x_t와 x_(t-1) 사이에 추가된 노이즈인 epsilon_theta를 구해서 저어기 algorithm2에 넣으면(alpha는 하이퍼파라미터여서 이미 알고 있고 sigam는 alpha를 통해 유도할 수 있음) 노이즈가 조금 제거된 x_(t-1)을 얻을 수 있다.
2 .Guided Diffusion
guided diffusion은 별거 없다. 그냥 쉽게 생각해보기로 했다.(ㅋㅋ) 원래 우리가 diffusion model에서 알 수 있듯이 우리가 구하고자 하는건 각 step 사이 추가된 noise 였고, 이는 사실 mean 값을 추정하려고 수식을 유도해서 얻을 수 있었다. 즉 시점 사이 추가된 noise에 대한 분포의 mean 값을 추정하는 것이 원래 목적인데, 추정된 mean 값을 그대로 활용하지 않고, "이쪽 방향으로 가세요" 라는 guide를 주는 것이다.
수식을 보자
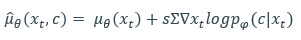
좌항에 mean_theta가 우리가 원래 추정한 mean 값이다. 여기에 1보다 큰 S에 잘 학습된 분류기(p(c|x))의 log likelihood를 x_t에 대해 미분한 값을 곱한 값을 mean_theta 에 더하여 guide를 주는 모습을 볼 수 있다.여기서 c는 이미지 classifier에서는 이미지의 label이고, text-condition generation에서는 이미지에 대응 되는 text이다. 즉 이 논문의 목적에 비유하자면 x는 이미지, c는 text인 pair 데이터에 대해서 학습을 미리 시킨 것이 p(c|x)라는 모델이 되는거고여기에 log를 씌우고 x에 대해 미분하게 되면 얘는 통계학에서 score가 되는 것이다.[1]
이해를 돕자면
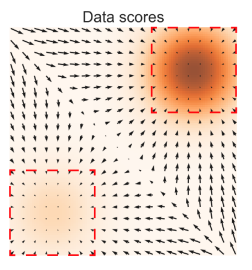
우리가 가지고 있는 데이터를 어떤 classifier에 학습을 시켜놓고 얘를 x에 대한 gradient를 구하게 되면 우리가 학습한 데이터에 대한 분포를 가리키는 "방향"이 나오게 된다. 그래서 Guided diffusion에서는 우리가 추정한 noise의 mean 값을 그대로 쓰는게 아니라 미리 학습시켜놓았던 분류기의 gradient 를 반영하여 계산된 mean 값을 쓴다는 것이 핵심이다.
3 .Classifier-free Guided Diffusion
이제부터 리뷰를 하는 중에 Classifier free guided를 'CF'라 표기하겠다. CF는 말그대로 분류기가 없는 diffusion model이다. 바로 전에 소개한 guided diffusion 같은 경우엔 diffusion 학습 모델과, 별도로 label-data pair가 학습된 classifier가 필요했다. CF는 diffusion model 1개로도 classifier의 guide를 받은 효과를 내겠다는 아이디어다.[2] 우리는 DDPM에서 mean을 epsilon으로 표현했었다. 그래서 guided diffusion에서 현재 우리의 상황을 표현한 수식은
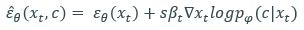
인데, 분류기 p(c|x)를 bayes rule로 풀어서 표현하고 어떤 규칙에 의해 다음과 같이 나타낼 수 있다.(이에 대한 자세한 내용을 다룬 link는 reference에)
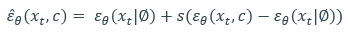
따라서 diffusion model로 구할 수 있는 것들로만 표현이 되었지만 classifier의 guide를 받은 효과를 낼 수 있다.
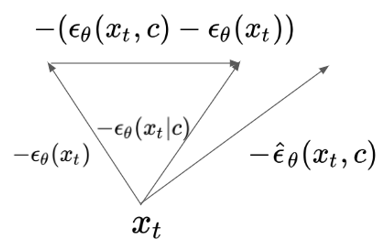
4 .CLIP guidance
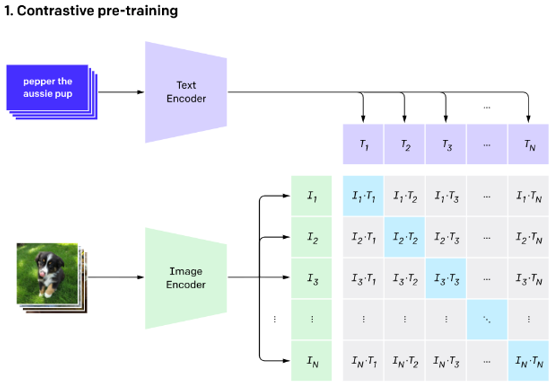
[3]CLIP이란 text-image pair 데이터에 대해 text encoder, image encoder가 있어 각 embedding 값의 True pair에 대해 similarity가 높아지도록 학습하는 모델이다.
unconditional diffusion model의 Reverse process시에 CLIP guidance를 받으면 text-conditional generation이 가능하다.
수식은 다음과 같다.
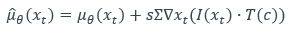
I와 T는 각각 CLIP의 image와 text encoder 이다. reverse process에서 noised data에 대해 CLIP을 학습시켜 guidance를 주는 것이 이 CLIP guidance이다.
Training
대망의 학습 부분을 읽으려고 논문을 봤는데 처음에는 아키텍쳐도 없어서 뭔 내용인지 전혀 감이 안왔다. 결국 reference를 따라다니면서 하나씩 찾을 수밖에 없었다. 논문 리뷰를 하면서 이런 과정이 제일 힘든 것 같다. training 을 이야기 하면서 저자는 갑자기 ADM을 채택했다고 한다. 도대체 ADM이 뭔지 알 수 없어서 reference를 찾아본 결과 [4]에서 나온 개념인데, ablated diffusion model이라는 뜻이다. 논문[4]에서는 이미지를 생성하는 diffusion model을 U-Net을 이용하여 좀 더 성능이 잘 나오도록 파라미터 튜닝을 했다. 그 모델이 바로 ADM이다.본 논문의 contribution이라고 생각되는 부분이 지금부터 나오는데, ADM은 x_(t-1) 시점의 데이터와 time embedding을 통해 노이즈와 분산을 추정했다. 본 논문에서는 text-conditional image generation을 가능케 하기 위해 text를 모델이 학습할 수 있도록 text embedding을 추가했다.
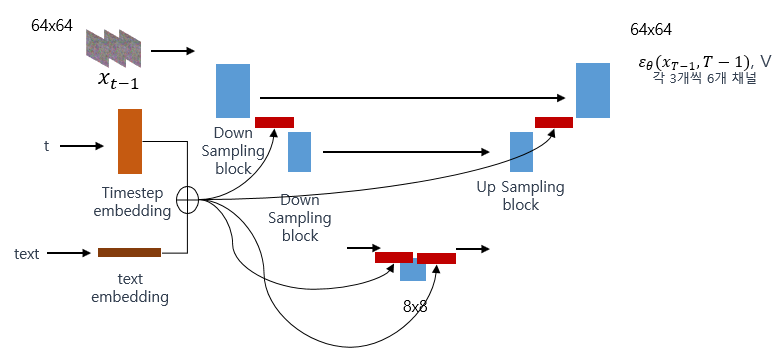
논문을 읽어보면 text embedding은 transformer의 output embedding이라고 한다. 이러한 embeded text를 기존 time step embedding에 더해 각각의 resblock에 concat 시켜 학습을 진행하다. 또, CF를 구현하기 위해 fine tuning을 해야하는데, 저자는 text sequence의 20%를 제외하고 empty sequence로 대체하여 추가 학습을 하였다.

Image inpainting을 하기 위해서 만들어진 모델을 fine tuning하는데, 기존 input에 masked RGB, mask channel을 추가하여 fine tuning을 진행했다고 한다.
Result
처음에도 말했듯이 본 논문은 CF와 CLIP guidance 의 성능을 비교했다고 했다. 이 두가지 guidance 전략을 통해 얻은 결과는 다음과 같다.

사진 설명에 있는 문장을 입력했더니 기존 text2image 모델인 DALL-E에 비해 GLIDE 기반 모델이 더 photorealistic한 것을 볼 수 있다. 특히 CF guidance를 받은 GLIDE가 기차의 난간을 표현하는 등 image detail이 더 높았다.

사진 설명에 있는 문장을 입력했더니 다음과 같은 결과를 얻을 수 있었다. CLIP guidance를 받은 GLIDE를 보면, 스키를 타는 사람들이 산에서 내려올 준비를 하고 있다는 것을 잘 묘사했지만, CF guidance를 받은 GLIDE를 보면 스키를 타는 사람들이 이미 산을 내려오고 있다. 즉 text를 잘 반영하지 못한 것인데, 저자는, 이는 CLIP guidance가 text - image 사이의 similarity를 기반으로 학습된 것에 영향이 있다고 말하고 있다. 논문에서 저자는 정량적 평가와 정성적 평가를 진행하여 CLIP guidance와 CF guidance를 비교하고 있다. 먼저 정량적 평가이다.
MS-COCO dataset의 caption을 가져와 zero shot 성능을 비교했을 때 결과는 다음과 같았다.
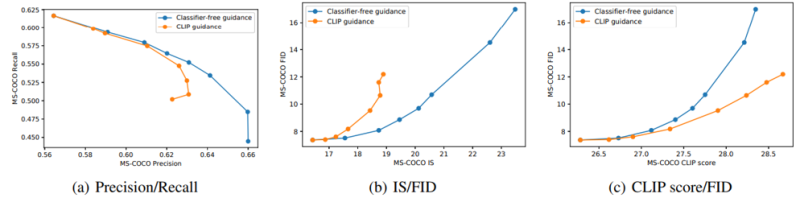
P/R, IS/FID trade off 에서는 CF가 최적이었지만 CLIP score/FID trade off에서는 CLIP guide가 최적이었다. MS-COCO image가 학습된 다른 GAN 기반 모델과의 비교에서 GLIDE가 이 데이터셋에 대해 명확하게 학습하지는 않았지만
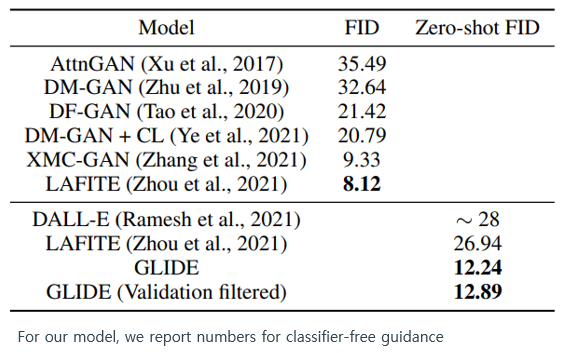
zero shot FID가 기존 모델의 최적 FID와 비교했을 때, 경쟁적인 FID를 얻었다고 저자는 말하고 있다.
다음은 정성적 평가이다. 사람에게 평가를 진행한 것인데,
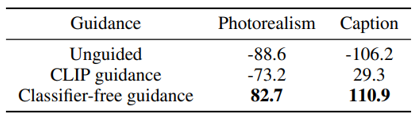
사람이 봐도 CF guide를 받은 모델에서 생성된 이미지가 CLIP guide 보다 photorealistic하고, text caption이 더 좋았다고 평가되어지고 있다.
Limitations
그럼에도 불구하고 GLIDE는 한계가 있었는데, GLIDE는 unusual한 object나 scenario를 묘사하여 이질적인 concept를 구성할 때 종종 이미지 생성이 부자연스럽다고 말하고 있다.

가운데 figure를 보면 쥐가 사자를 사냥하는 사진이 현실적으로 없기 때문에 이러한 이질적인 concept는 아무리 GLIDE라 해도 묘사를 하지 못했다. 또한 저자는 GLIDE가 이미지를 생성하는데, 15초가 걸리는데 이는 GAN 기반 모델에 비해 느리다고 말하고 있다.
Conclusion
•본 논문을 한마디로 정의하면 무엇인가?
두 Guidance strategy가 적용된 Diffusion model의 비교
•본 논문이 가장 크게 기여한 부분은 무엇인가?
text-condition image generation이 가능한
diffusion model
•본 논문의 문제점 혹은 부족한 부분은 무엇인가?
(Guided)Diffusion model 개념, diffusion model의 train, inference 과정을
모두 안다는 전제하에 기록되어 있어 이해하기 어려웠음
또한 unconditional generation이 가능한 Classifier free guidance를 구현했지만
조건 없이 이미지를 생성하는 figure가 없어 이해가 완전히 되지 않았음
이에 Classifier free guidance 방식이 CLIP 같은 classifier 없이
DDPM처럼 1개의 모델(U-Net)로 학습할 수 있다는 면에서
unconditional generation이 가능하다로 이해해도 되는지 모르겠음
이미지를 생성하는데 15초로 오랜 시간이 걸린다고 하는데 그 이유에 대한 제시가 없음
DALL-E와의 정량적 성능비교를 제시하지 않았음
•본 논문과 관련된 본인의 아이디어는 무엇인가?
이미지 생성 시간이 긴 이유가 diffusion process에서
denoising 과정이 너무 까다롭고, 오래 걸린다고 생각함
따라서 x_t 에서 x_(t-1) 로 한 단계씩 denoising 하는 것보다
몇 단계를 건너서 denoising 하는 학습법을 고민해보면 좋을 것 같음
참고문헌
[1] Song, Yang, and Stefano Ermon. "Generative modeling by estimating gradients of the data distribution." Advances in Neural Information Processing Systems 32 (2019).
[2] Ho, Jonathan, and Tim Salimans. "Classifier-free diffusion guidance." NeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications. 2021.
[3] CLIP blog : https://openai.com/blog/clip/
[4] Dhariwal, Prafulla, and Alexander Nichol. "Diffusion models beat gans on image synthesis." Advances in Neural Information Processing Systems 34 (2021): 8780-8794.
[6] Ho, Jonathan, Ajay Jain, and Pieter Abbeel. "Denoising diffusion probabilistic models." Advances in Neural Information Processing Systems 33 (2020): 6840-6851
'Paper Review' 카테고리의 다른 글
| [Review] TokenLearner: What Can 8 Learned Tokens Do for Images and Videos (0) | 2023.01.18 |
|---|---|
| [Review]Attention-based Auto encoder Topic Model for Short Text (0) | 2022.12.22 |
| [Review]ATM: Adversarial-neural Topic Model (1) | 2022.12.21 |
| [Review] Learning document representation via topic-enhanced LSTM model (1) | 2022.12.20 |
| [Review]Topic Modeling Meets Deep Neural Network: A Survey (1) | 2022.12.20 |



