
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- 의료정보
- causal reasoning
- 패혈증 관련 급성 호흡곤란 증후군
- 분산 학습
- machine learning
- multi gpu
- causal machine learning
- nccl 설치
- gru-d
- doubleml
- Time Series
- nccl 업그레이드
- pytorch
- 의료
- nccl 업데이트
- causal ml
- causal inference
- 불규칙적 샘플링
- NTMs
- 리뷰
- Transformer
- 의료 의사결정
- first pg on this rank that detected no heartbeat of its watchdog.
- 인과추론 의료
- netflix thumbnail
- GaN
- ERD
- irregularly sampled time series
- 딥러닝
- 토픽모델링
Archives
- Today
- Total
데알못정을
Pytorch를 이용한 Dropout 효과 시각화(코드구현) 본문
728x90
pytorch를 이용하여 신경망을 설계하고, 학습과정에서 dropout을 지정할 때와, 그렇지 않을 때를 비교해서drop out의 효과를 공부해보자. 먼저, dropout이란 무엇인지 살펴보면 신경망 뿐만 아니라 머신러닝에서 자주 발생하는 문제 중에 'overfitting'이 있다. dropout은 이를 신경망에서 해결하기 위한 방법인데, 어떻게 하냐면

오른쪽 그림과 같이 일정한 비율로 훈련세트에서 무작위로 노드를 제거하면서 학습을 이어나가는 것이다. 이렇게 되면 활성화된 노드만 학습에 참여하여 과적합을 방지할 수 있다. 테스트 셋에서는 모든 뉴런에 신호를 전달하는 대신 훈련때 삭제한 비율을 각 뉴런에 곱해서 출력을 한다. 실제로 drop out을 할때 train, test loss의 변화는 어떤지 보자.
[Dropout x]
import torch
from torch import nn, optim
from sklearn.model_selection import train_test_split
from torch.utils.data import TensorDataset, DataLoader
X = digits.data
y = digits.target
X_train, X_test, Y_train, Y_test = train_test_split(X,Y,test_size = 0.2)
X_train = torch.tensor(X_train, dytpe = torch.float32)
X_test = torch.tensor(X_test, dytpe = torch.float32)
Y_train = torch.tensor(Y_train, dytpe = torch.float32)
Y_test = torch.tensor(Y_test, dytpe = torch.float32)
"""신경망 모델 구성"""
k=100
net = nn.Sequential(
nn.Linear(64,k),
nn.ReLU(),
nn.Linear(k,k),
nn.ReLU(),
nn.Linear(k,k),
nn.ReLU(),
nn.Linear(k,k),
nn.ReLU(),
nn.Linear(k,10)
"""손실함수"""
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters())
ds = TensorDataset(X_train, Y_train)
loader = DataLoader(ds, batch_size = 32, shuffle = True)
"""훈련루프"""
train_losses = []
test_losses = []
for epoch in range(100):
running_loss = 0.0
for i ,(xx,yy) in enumerate(loader):
y_pred = net(xx)
loss = loss_fn(y_pred, yy)
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss+=loss.item()
train_lossed.append(running_loss/i)
y_pred = net(X_test)
test_loss = loss_fn(y_pred, Y_test)
test_lossed.append(test_loss.item())결과
다음과 같이 학습데이터 loss(파란선)은 epoch를 반복할 수록 loss가 감소한다. 그러나 test loss는 어느 순간까지는 감소하다가 반대로 증가하는 경향을 볼 수 있다. 이는 과적합 현상이 일어난 것이다.
[Dropout o]
"""신경망 모델 구성"""
k=100
net = nn.Sequential(
nn.Linear(64,k),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(k,k),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(k,k),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(k,k),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(k,10)
"""손실함수"""
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters())
ds = TensorDataset(X_train, Y_train)
loader = DataLoader(ds, batch_size = 32, shuffle = True)
"""훈련루프"""
train_losses = []
test_losses = []
for epoch in range(100):
running_loss = 0.0
net.train()
for i ,(xx,yy) in enumerate(loader):
y_pred = net(xx)
loss = loss_fn(y_pred, yy)
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss+=loss.item()
train_lossed.append(running_loss/i)
net.eval()
y_pred = net(X_test)
test_loss = loss_fn(y_pred, Y_test)
test_lossed.append(test_loss.item())drop out을 모델 설계시 넣어줄 경우에 주의할 점은 훈련루프에서 학습 할때는 '모델이름.train', 추론할때는 '모델이름.eval()'을 꼭 해줘야 한다. 이렇게하면 추론할때 drop out이 작동하지 않는다.
결과
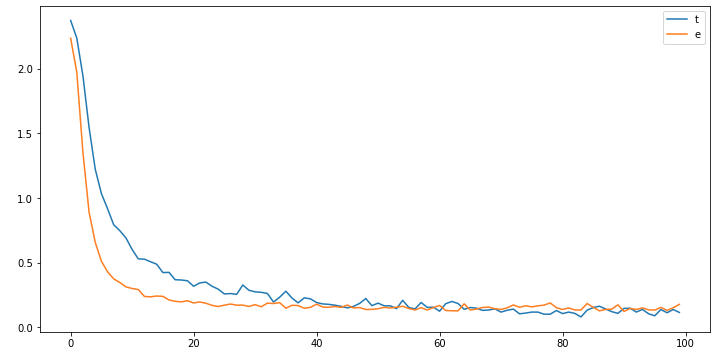
test 데이터에 대해서도 loss가 잘 줄어들었다.
dropout은 과적합을 잘 막을 수 있는 도구다!
728x90
'Coding' 카테고리의 다른 글
| 파이썬 pivot table 생성 시 Memory error 해결하는 방법 (0) | 2023.07.06 |
|---|---|
| 내가 자꾸 까먹어서 올리는 주피터 노트북 가상 환경 만드는 법 (0) | 2023.07.02 |
| [오류해결]No module named ipykernel (1) | 2022.11.09 |
| 신경망 특정 layer 결과 값 출력하기 (0) | 2022.10.03 |
| pytorch-SGD(확률적 경사하강법 구현) (0) | 2022.09.30 |
'Coding' Related Articles
more



Comments