

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- doubleml
- Time Series
- multi gpu
- 의료
- first pg on this rank that detected no heartbeat of its watchdog.
- causal ml
- NTMs
- 딥러닝
- causal reasoning
- causal inference
- nccl 설치
- irregularly sampled time series
- nccl 업데이트
- 의료 의사결정
- ERD
- gru-d
- Transformer
- 리뷰
- nccl 업그레이드
- 불규칙적 샘플링
- machine learning
- 의료정보
- 인과추론 의료
- 분산 학습
- GaN
- causal machine learning
- 토픽모델링
- netflix thumbnail
- pytorch
- 패혈증 관련 급성 호흡곤란 증후군
- Today
- Total
데알못정을
[Review] Using machine learning for the early prediction of sepsis-associated ARDS in the ICU and identification of clinical phenotypes with differential responses to treatment 본문
[Review] Using machine learning for the early prediction of sepsis-associated ARDS in the ICU and identification of clinical phenotypes with differential responses to treatment
쩡을이 2024. 6. 25. 00:42
Motivation/Background
급성 호흡 곤란 증후군(Acute Respiratoty Distress Syndrom, ARDS)는 급격히 진행되는 호흡 부전과 폐 부종, 미만성 폐포 손상, 감염 세포 침윤을 특징으로 하는 중환자실에서 가장흔한 호흡기 증후군이다. 패혈증(Sepsis)는 ARDS의 흔한 위험 요소 중 하나이며, Sepsis associated ards는 매우 높은 사망률을 가지고 있으며 폐 손상으로부터 회복하기 쉽지 않기 때문에 non sepis ards보다 더 심각하다. 진단과 형태(Penotypic) 분류는 호흡기 중증 치료에서 주요 연구 방향으로 남아 있다. 특히, sepsis associated ARDS와 같은 높은 사망률 조건은 반드시 적극적으로 정밀 진단되어져야 한다. sepsis와 관련된 ARDS를 조기에 정확히 예측하는 것 뿐만 아니라 그것의 임상적 subgroup들 을 분류하는 것은 치료의 효율성을 위해 매우 중요하다.
Literature Review
Medical field에서 AI와 머신러닝을 이용하여 질병의 발병을조기에 예측하는 연구와 clustering을 통해 임상 의사 결정을 돕는 연구들이 많이 이루어져 왔으나, 머신러닝을 통해 sepsis associated ards를 진단하고 예측하는 연구와 그것의 clinical subtype을 연구하는 사례는 없었고, 단지 전체 ARDS 인구에 초점을 맞출 뿐이었다. 하지만 이러한 연구들은 robustness의 부족, 윤리적 우려, 부족한 모델의 해석력과 같은 문제들이 있었다. Seymour et al., 2019는 임상 결과와 반응 패턴들과 관련된 군집 분석을 통해 4가지 sepsis의 임상적 penotypes를 식별하였다. Calfee et al., 2014는 ARDS 환자를 일반적인 고감염성, 저감염성 type으로 분류하였으나 그것의 생리학적 penotypes 정의는 sTNFR-1과 Iinterleukin과같은 일상적으로 이용가능 하지 않거나 bedside에서 빠르게 정량화 할수없는 것들인 class-defining 변수들로써 plasma buomarker를 활용했다. 궁극적으로 이러한 분류 시스템은 임상 적용성에 한계가 있었다. Liu et al. 2021은 ARDS 환자를 3가지 clinical phenotypes로 분리하는 새로운 방법을 제안했다. 그들은 ARDS의 임상적 phenotype이 무작위 intervention들에 서로 다르게 반응하는 것과 관련있다고 결론지었다. 하지만 이 연구는 전체 ARDS 모집단에 대해 수행되었다.
본 연구에서는 sepsis associated ards 환자들을 위한 조기 진단 모델 구축을 위해 sepsis 환자와 sepsis associated ards 환자들에게서 빠르고, 쉽게 얻을 수있는 임상 지표를 사용하였다. 또한 이러한 환자 군에서 치료에 대한 서로 다른 반응과 임상적 예후가 다를 수 있음을 가정하고, 여러가지 phenotype을 식별하기 위해 subgroup classification(즉, clustering)을 수행했다.
Method
- Study design
본 연구는 eICU database를 이용하여 sepsis associated ARDS 조기 예측 모델을 구축하고, 동시에 이 환자군들을 clustering하여 subgroup을 식별하였다. 이때는, 조기 예측 모델의 주요한 예측 변수들만을 활용하였다.(이유는 제공하지 않았다.) clustering을 통해 phenotype을 식별한 후에는, 그 그룹 사이에 in-hospital mortality, 초기 PEEP level, Lab test result들에 차이가 있는지 분석을 진행하였다. 또한 이러한 결과들은 MIMIC-IV database를 통해 외부 검증이 수행되었다.
- Patient population
ICD-9 code를 이용하여 sepsis, ARDS, sepsis associated ARDS 환자를 식별하였다. 그 과정에서 환자가 입원한 중환자실이 MICU(medical ICUs), MSICU(Medical-Surgical ICUs)인 경우만 분석에 포함시켰다. cardiothoracic과 cardio-surgical ICUs는 분석에서 제외했는데, 이는 sepsis의 뚜렷한 양상이 조금 다른 환자들이 포함되어 Bias가 될 수 있기 때문이다. MIMIC-IV에서 식별된 sepsis 환자는 sepsis-3 기준에 따라 진단되었고, eICU에 있는 sepsis 환자는 APACHE IV dataset에 기록된 입원 진단 정보에 따라 식별되었다. 1일 미만 체류한 환자 또는 입원 후 1일 이내에 ARDS가 온 환자는 분석에서 제외되었다. 또한 한명의 환자는 병원에 입원하면 중환자실에 입원하고 퇴원하는 과정을 여러번 거칠 수 있는데, 본 연구에서는 단 1번 ICU에 입원한 환자만을 분석에 포함시킴으로써 같은 환자에대해 중복된 분석이 이루어지는 것을 방지했다.
- Predictor variables
본 연구에서는 데이터 이용가능성과 임상 지표들의 missing 여부를 평가하여 최종적으로 27가지의 변수를 선정하였다.: age, gender, body mass index(BMI), hypertension, diabetes, cancer, APACHEIV/APSIII, macimum and minimum values of albumin, bicarbonate(HCO3), lactate, bilirubin, creatinine, glucose, platelet, prothrombin time(PT), blood urea nitrogen (BUN), white blood cell count(WBC). 또한 모델의 예측 적시성을 반영하기 위해 입원 후 24시간 이내 lab 변수들의 최대 값, 최소 값을 포함하였다. APACHE-IV index는 MIMIC-IV에는 식별되지 않았기 때문에 APSIII 값이 대신 사용되었다.
- Model training and testing
sepsis associated ARDS 진단모델 구축을 위해 eICU 내 환자들을 7:3으로 분할하여 training set, testing set으로 사용하였다. 또한 correlation algorithm(Logistic Regression과 같은)을 fitting한 후 추출된 weight를 사용하여 sepsis associated ARDS를 예측하는데 중요한 인자를 추출하여 clustering에 사용하였다. 저자들은 총 5가지 모델을 사용하였다.: Naive Bayes, Logistic Regression, Gradient Boosted Trees, AdaBoost, Random Forest. Model performance는 AUROC, accuracy, sensicivity, specificity를 활용하였다. 가장 예측력이 좋은 모델을 선별하여 MIMIC-IV에 외부 검증을 하였다.
sepsis associated ARDS환자들의 clinical grouping을 구성하는 단계에서, 저자들은 K-means 알고리즘을 위에서 선별한 중요 변수를 활용하여 구현하였다.(클러스터링을 더 잘되게 하려고 한 것인지?-> 노이즈 감소 효과가 있어 클러스터링이 잘 됨, 중요한 변수만 분석에 포함되어 군집 간 차이 해석이 매우 쉬워짐) 최적의 phenotype들이 도출된 후에는, 각각의 clinical한 특징들과, outcome(입원 기간 중 사망률 및 초기 PEEP 설정수준 등)들을 분석하였다.
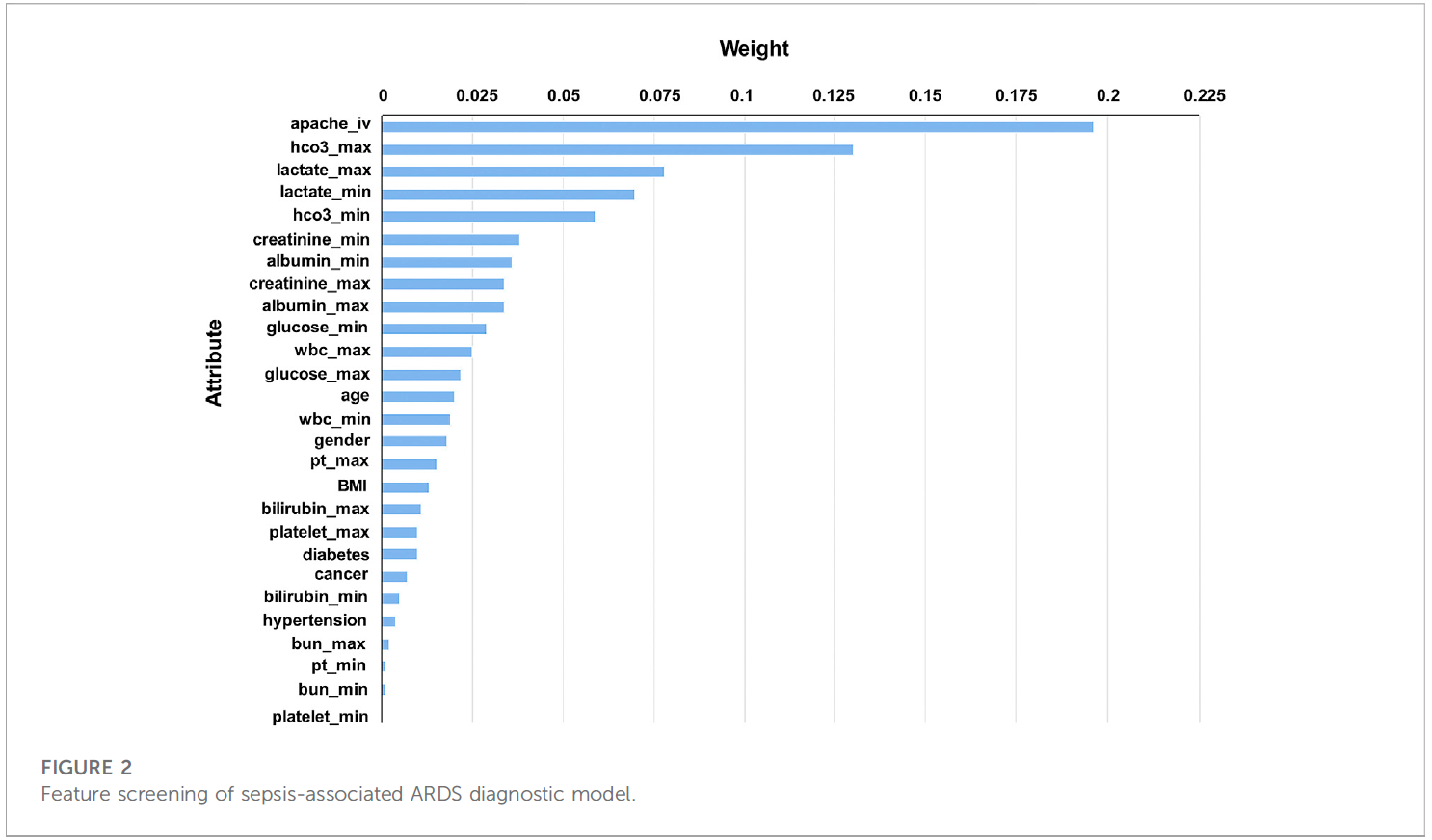
Result
- Participants
총19,249명의 패혈증 환자가 eICU에 포함되었고, 5,497명의 sepsis associated ARDS 환자가 포함되었다. MIMIC-IV의경우 총 11,935명의 패혈증 환자가 포함되었고, 2,699명의 sepsis associated ARDS 환자가 포함되었다. 감염의 원천은 gastrointestinal, cutaneous/soft tissue, pulmonary, gynecologic, renal, urinary tract infection, abdominal infection과 알 수 없는 원인 등이 포함되었다. eICU에 대해서, 전체 패혈증 환자의 사망률과 LOS가 16.84%, 2.3일로 식별되었으며, sepsis associated ARDS 환자의 경우 각각 27.31%, 3.4일로 식별되었다. MIMIC-IV에 대해서 패혈증 환자의 사망률과 LOS는 16.51%, 2.1일, sepsis associated ARDS 환자에 대해서는 각각 22.05%, 2.9일로 식별되었다.(두 데이터 모두 sepsis associated ARDS 환자의 사망률과 LOS가 높고, 길었다.)
- Establishment and verification of sepsis associated ARDS diagnostic model
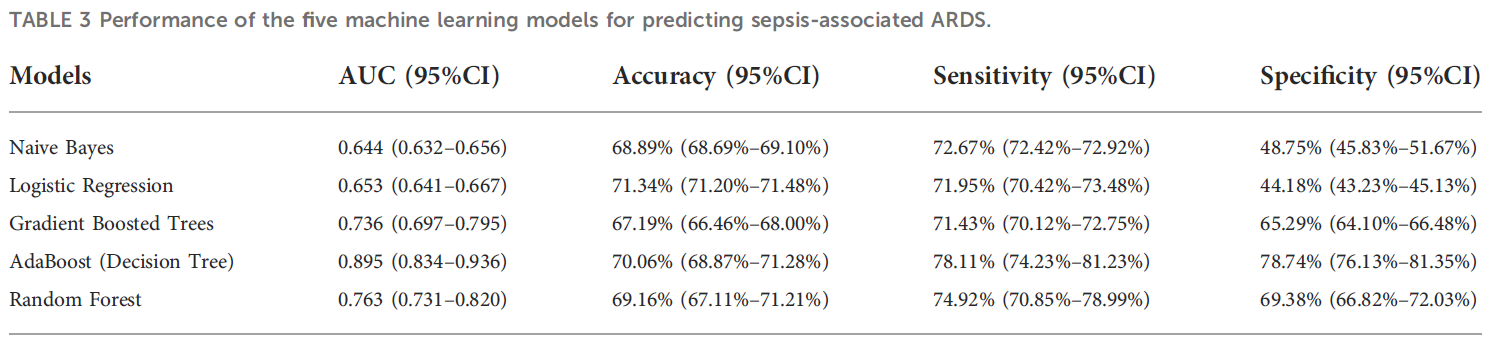
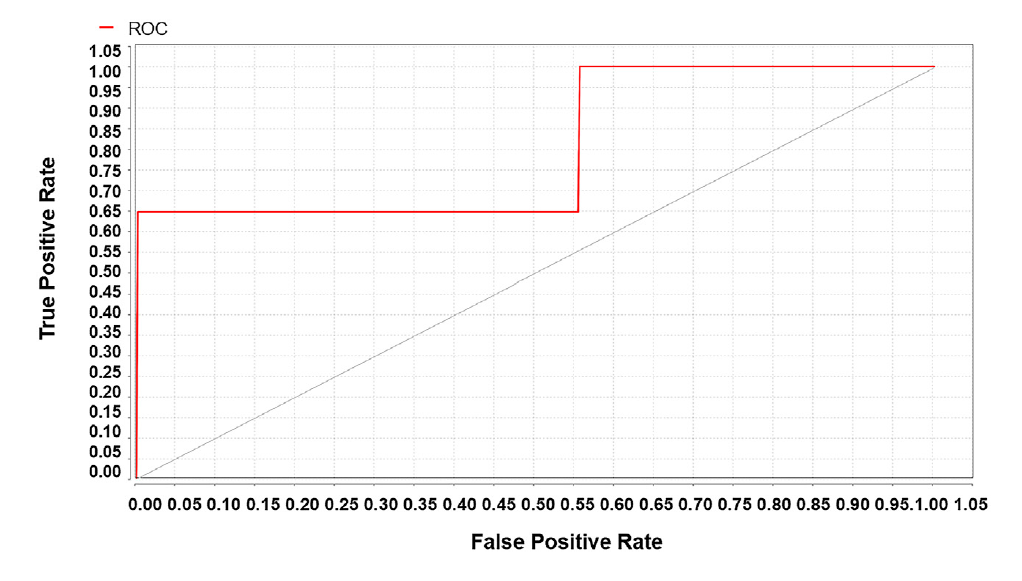
eICU 내부 검증 결과 Adaboost의 성능이 대체적으로 우수했기 때문에, 이를 최종 모델로 선정하였으며, MIMIC-IV에 대해 평가한결과 AUC가 0.804로, 매우 높은 수준의 일반화 성능을 보여주었다.
- Derivation and validation of sepsis associated ARDS phenotypes
Phenotypes 분석에는 sepsis associated ARDS 환자만이 포함되었다.(eICU: 5,947명, MIMIC-IV: 2,699명) clustering에 관하여 임상에서 빠르게 이용가능한 점, missing value의 빈도 등을 평가하여 주요 변수 8개를 선정하였다. (위에서 미리 선별한 14가지 주요 변수를 기반으로 다시 평가한 듯) 최적의 군집 갯수는 Gap statistics(https://stackoverflow.com/questions/15376075/cluster-analysis-in-r-determine-the-optimal-number-of-clusters/15376462#15376462, https://towardsdatascience.com/k-means-clustering-and-the-gap-statistics-4c5d414acd29) 를 통해 3개로 추정되었다.
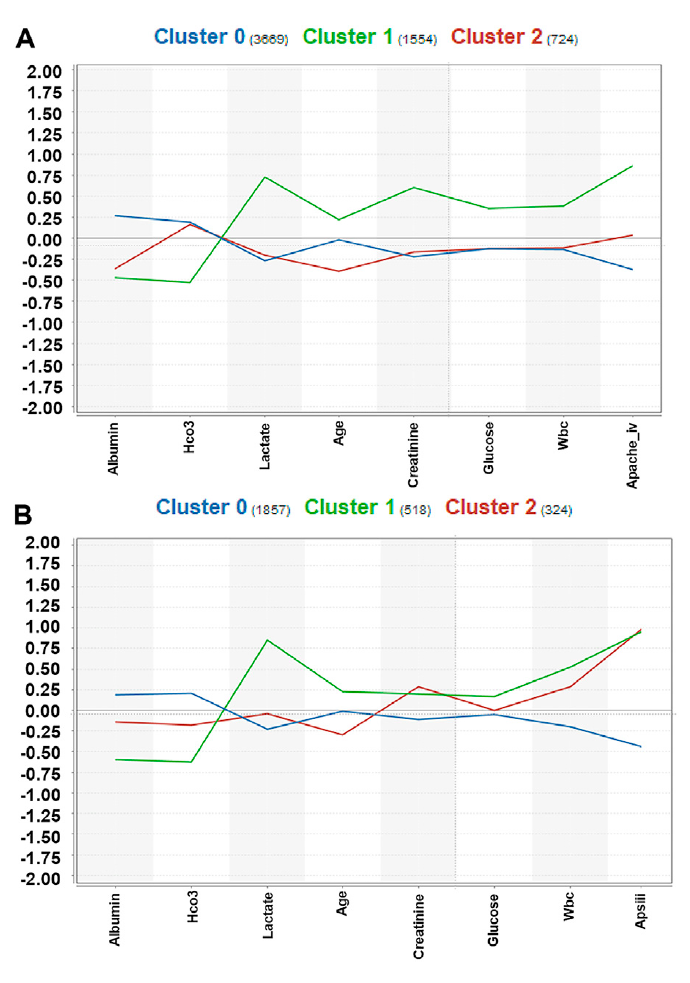
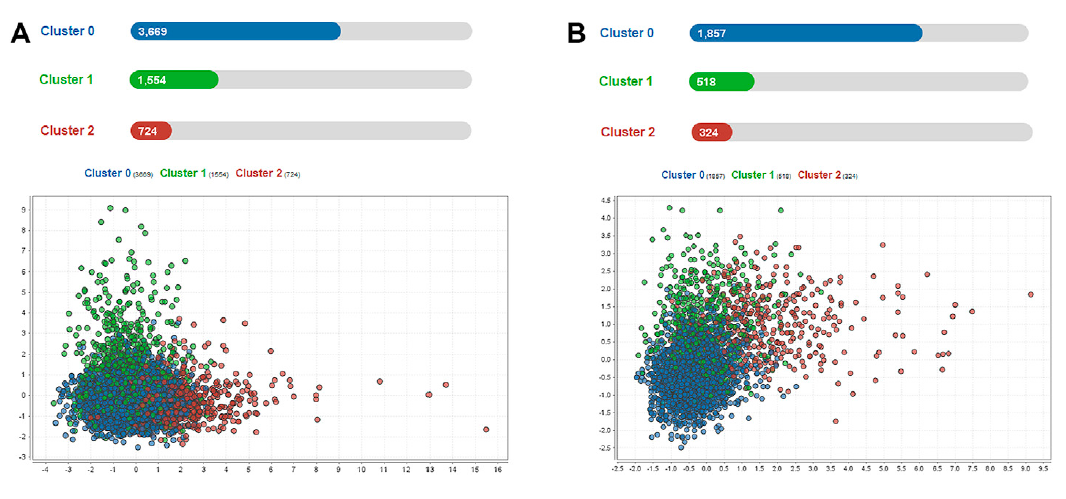
(그렇게 잘 구분되지는 않는 듯)
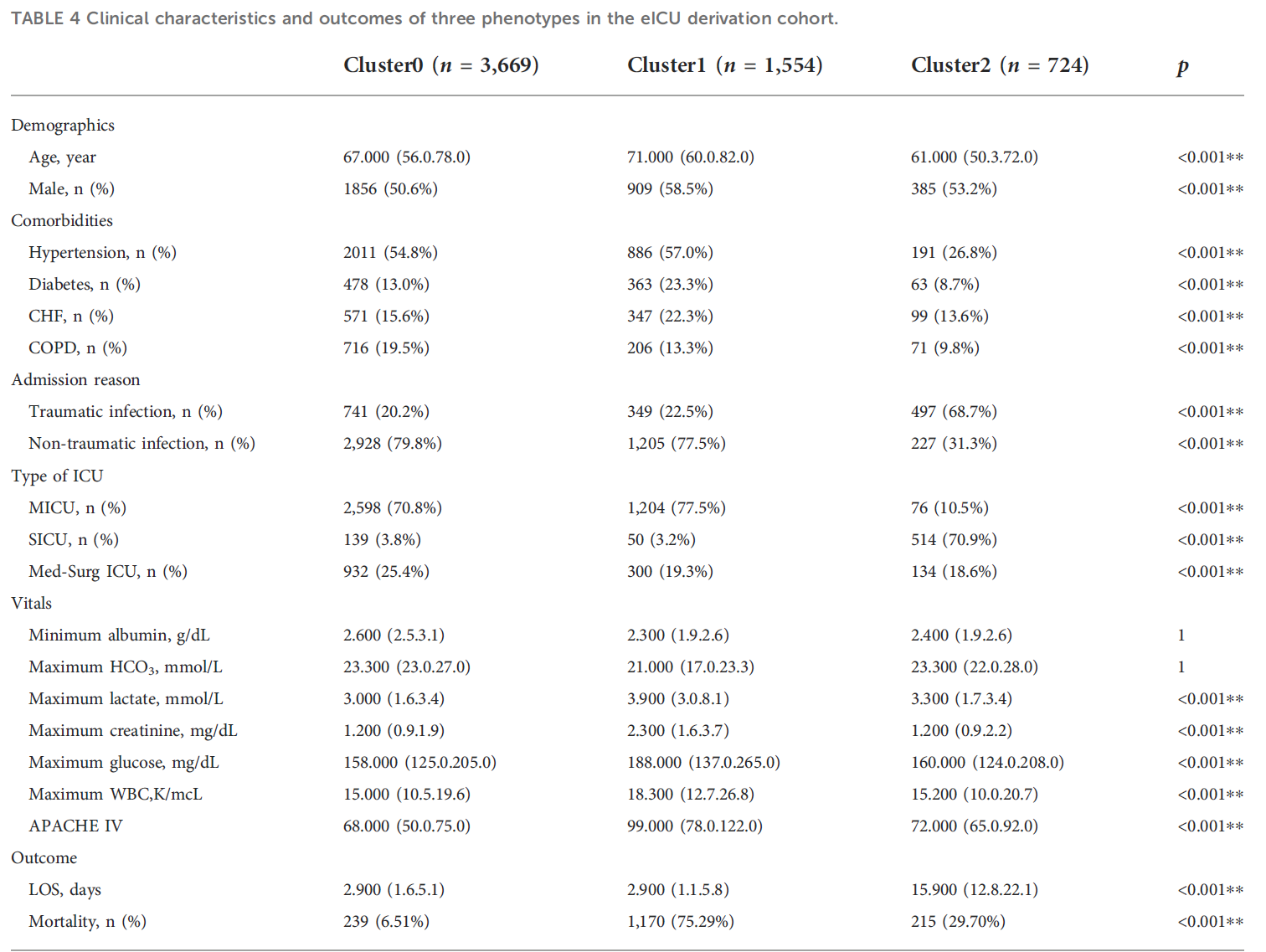
사용한 변수들과 생성된 군집간 통계 값들이다. Cluster 0은 환자의 나이와 만성 질환 빈도가 Cluster 1과 2 사이에 있었다. 비 외상에 의한 감염이 주된 입원 원인이었으며, 주로 MICU에 입원하였다. Lab 측정값들은 Lactate, glucose, WBC에서 가장 낮은 수준을 보였고, 사망률이 제일 낮은 그룹이었다.(저 위험 군으로 라벨을 부여할 수 있음) Cluster 1은 가장 높은 나이의 환자들이 주로 포함되었고, Cluster 0과 마찬가지로 비 외상에 의한 감염이 주된 입원 원인이며 주로 MICU에 입원하였다. 또한 동반 만성 질환 비율과 위에서 언급한 Lab 측정 값과 사망률이 세 가지 군집 중 가장 높은 수준이었다. (고 위험 군으로 라벨을 부여할 수 있음) Cluster 2는 가장 낮은 동반 만성 질환 비율을 보였고, 특이하게 외상에 의한 감염이 주된 입원 원인이었으며, SICU에 주로 입원을 하였다. 입원 기간은 가장 길었으며 그에 반해 사망률은 매우 낮은 그룹이었다. (위험 성이 0과 1 사이로 라벨을 부여할 수 있음)
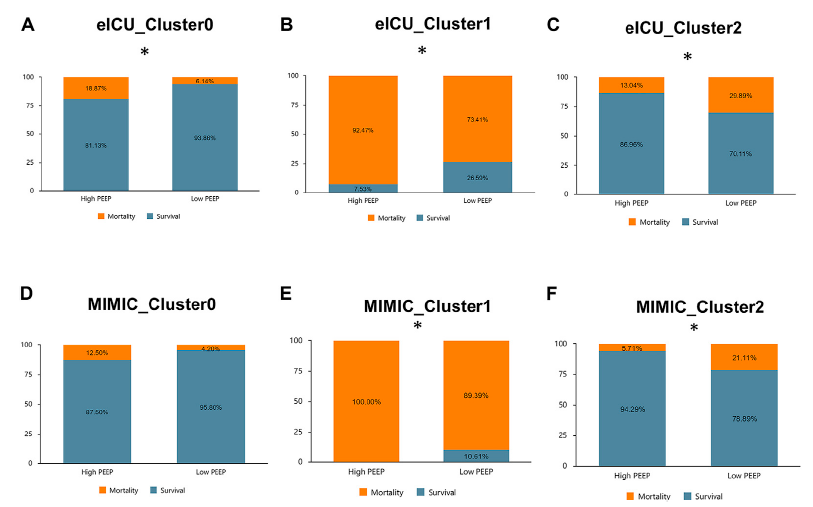
논문에서는 군집간 임상적 특징에 대해 인사이트를 이 파트에서는 밝히지 않았기 때문에 Discussion으로 넘어간다.
Discussion
이 논문의 Discussion에서는 주로 machine learning 모델들 중 왜 Adaboost가 가장 잘 나왔는지, 클러스터링에 활용한 주요 인자 8개는 어떤기준으로 설정하였는지, 임상적으로 정의된 ARDS의 type과 논문에서 도출된 cluster 간의 비교를 통해 공통점을 찾고, 동시에 각 군집에 따라 초기 PEEP 값 설정 방향에 대한 인사이트에 대해 설명하고 있었다. 그 중 가장 후자에 대해서 언급하자면, 우선 폐포 재개폐 가능성(Alveolar recruitability)에 대한 사전 지식이 필요하다. 쉽게 말해 폐포를 가스 교환 상태로 만드는 것으로, mild한 ARDS를 가진 환자들에게서는 폐포 재개폐 가능성이 매우 낮은 반면, moderate or sever ARDS 환자에게서는 매우 높다.
경증 ARDS 환자의 경우, 폐 조직 손상이 비교적 적기 때문에 이미 대부분의 폐포가 열려 있거나, 이미 기능을 유지하고 있다. 따라서, 기계적 환기나 다른 치료 방법을 통해 추가로 열 수 있는 폐포의 양이 적다. 반면에 중등도 및 중증 ARDS 환자에서는 폐 손상이 심하고 많은 폐포가 붕괴되어 있다. 따라서, 기계적 환기, 특히 고양압(PEEP, Positive End-Expiratory Pressure)과 같은 전략을 통해 더 많은 폐포를 다시 열 수 있는 잠재력이 높다.
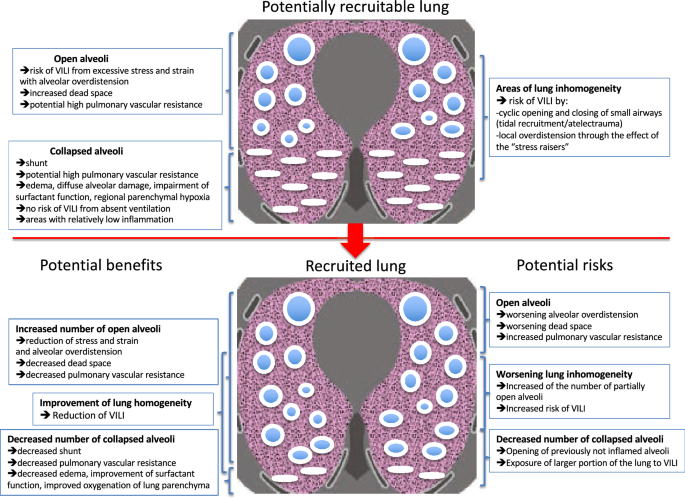
본 연구에서 sepsis associated ARDS 환자 subtype 중 cluster 0(저위험군) 환자들은 낮은 폐포 동원력을 가지고 있으며 이는 Calfee et al. 2014에서 제안한 저염증성 phenotype 분류와 일치했다. 이 그룹은 사망률이 매우 낮고, 낮은 PEEP 값을 가지고 있었다. Liu et al 2021의 Type 1 ARDS 분류에 따르면 낮은 PEEP 값을 가지는 환자들은 폐포 팽창을 유지하기에 충분하기 때문에 높은 PEEP를 가지는 환자들 보다 60일 이내 사망률이 낮은 것으로 보고되었다. 반면에, Cluster 1과 2에 해당하는 환자들은 고 염증성 ARDS 환자로, 더 중증도와 사망률이 Cluster 0보다 더 심각한 것으로 분석할 수 있다. Writing group for the Alveolar Recruitment for ARDS Trial ART Investigators Laranjeira et al., 2017 또한 moderate 한 ARDS가 severe한 상태로 변화한 환자들에게서 높은 PEEP를 사용한 것이 산소 공급이 있었다는 것이지만 안타깝게도 사망률이 매우 높았다는 것에 주목했다. 저자들은 이러한 상황이 아마도 폐의 형태학을 잘못 분류했기 때문에 발생했다고(즉, ARDS의 phenotype) 생각했다. 따라서 moderate 한 ARDS와 severe한 ARDS의 더 구체적인 환자 분류 방식이 필요하다고 강조했다. 이에 저자들은 본인들의 Cluster 1과 2가 각각 severe, moderate한 환자로 분류되었다고 주장한다.
먼저, Cluster 2는 높은 폐의 재확장 가능성을 가지고, 적은 나이를 가진, 그리고 주된 입원 원인이 외상에 의한 감염으로, Cluster 0에 비해 더 심각한 환자 군이었다. 따라서 이 환자 군에게는 높은 PEEP를 사용하는 것이 이점이 있다고 한다. 이는 그들의 임상 경험에 따른 것으로, 외상에 의한 감염으로부터 ARDS가 발생한 환자들에게는 더 나은 폐 재확장 능력을 가지고 있기 때문에 이러한 ARDS 환자들에게는 높은 PEEP을 선택하는 것이, 폐포의 주기적인 붕괴로 인한 전단력을 줄이고, 과도한 경폐압으로 인한 인공호흡기 관련 폐 손상을 방지할 수 있다고 한다.
Cluster 1의 환자들은 상태가 가장 심각하며, 매우 높은 사망률을 보인다. 이들은 높은 PEEP을 견디기 어려울 수 있으며, 높은 PEEP이 주는 부작용이 이점보다 크다.
따라서, sepsis associated ARDS 환자들을 분류한 결과, Cluster 0과 1에서는 낮은 PEEP이 더 유리하고, Cluster 2에서는 높은 PEEP이 더 좋다. 저자들은 이 연구를 소프트웨어와 기타 임상 도구로 전환하여, sepsis associated ARDS 환자들의 식별 및 군집화를 통합하여 의사들의 진단과 치료를 돕는 것을 고려한다고 한다.
Personal opinions
개인적으로 이 연구를 통해 다음 연구주제에서 어떤 문제를 해결해야할지, 어떤 연구 결과가 의료진에게 도움이 될지 생각해보는 계기가 되었다.
1) Missing value: 저자들은 본 연구의 한계로써, 중요할 수 있는 Laboratory paremeter들을 상당 부분 제거했다고 한다. 그 이유는 그 측정 값이 50% 이상 결측 값이었기 때문이다. 임상 현장에서 그 변수들을 측정하지 않은 것이 또 다른 정보가 될 수 있겠지만, 이러한 정보의 손실은 데이터 분석가 입장에서는 매우 난감한 문제이다. missing value를 처리할 수 있는 새로운 분석 프레임워크가 필요하다. 2) ethical concerns: 본 연구에서는 correlate model의 weight가 낮다는 이유로 gender를 cluster 분석에서 제외하였다. 이는 분석에 편향을 줄 수 있다. 3) 단순한 예측 과업이 아닌 Phenotyping: Fancy한 알고리즘(딥러닝 기반 등)을 통한 예측으로 좋은 성능을 내는 것은 임상의에게 큰 매력은 없는 것 같다. 대신에 그들이 공감하고, 납득할 수 있는 연구 결과를 도출하는 것이 그들의 구미를 당기게 하는 방법인 것 같다. 본 연구에서 도출한 phenotype들은 그 역할을 할 수 있었다. 어떤 군집에게는 PEEP 값을 낮게 설정하는 것이 좋고, 어떤 군집에게는 높게 설정하는 것이 좋았는데, 이는 모두 임상 지식과 일치했다. 여기에서 더 나아가 데이터를 통해 임상 지식에서는 발견되지 않은 새로운 인사이트를 발견한다면 아주 좋은 기여점이 될 것 같다. (PEEP와 같은 Intervention을 초점으로 Phenotype 별 어떤 치료를 하는 것이 좋은지 등, 일부러 어떤 환자의 기록에서 특정 Intervention을 임의로 바꾸었을 때, 모델이 어떤 판단을 하는지 관찰해보는 것도 매우 흥미로울 것 같다. 예상되지 않은 결과를 모델이 도출했다면, 현재 모델이 어떤 편향을 갖고 있는지 분석할 수 있을 것이다.)
Reference
[1] Bai, Yu, et al. "Using machine learning for the early prediction of sepsis-associated ARDS in the ICU and identification of clinical phenotypes with differential responses to treatment." Frontiers in Physiology 13 (2022): 1050849.
[2] 임채만. "심포지움: 급성호흡부전; 급성호흡곤란증후군의 저산소증치료와 폐포모집." 대한내과학회 추계학술발표논문집 2001.2 (2001): 689-692.



